地球资源数据云——数据资源详情
H&M 报废产品数据集
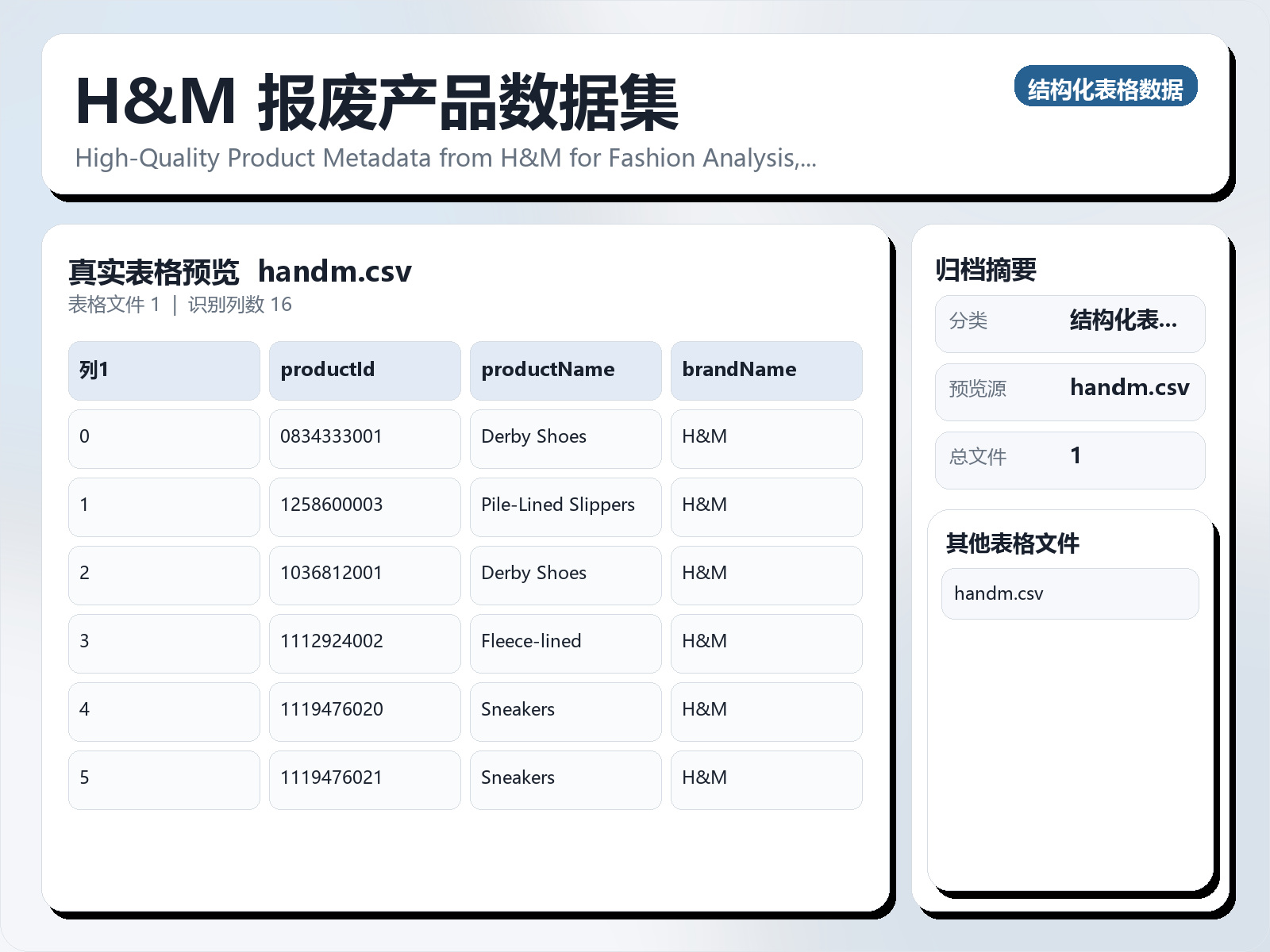
该数据集《H&M Scrapped Product Dataset》主要用于监督学习任务,数据形态以图像为主,应用场景偏向环保分类。 题目说明:High - Quality Product Metadata from H&M for Fashion Analysis, NLP, and E - Commerce 任务类型:图像监督学习。 建议流程:先检查类别分布与脏样本,再用迁移学习(如 ResNet/EfficientNet)建立基线。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:handm.csv。 This dataset contains a rich and structured catalog of H&M products scraped directly from their official website. It includes detailed metadata for each product such as: Product ID, Name, and Brand Product URL and Price Stock Availability and Coming Soon Flag Color Name, Available Color Variants, and Color Shades
摘要概览
该数据集《H&M Scrapped Product Dataset》主要用于监督学习任务,数据形态以图像为主,应用场景偏向环保分类。 题目说明:High - Quality Product Metadata from H&M for Fashion Analysis, NLP, and E - Commerce
任务类型:图像监督学习。
建议流程:先检查类别分布与脏样本,再用迁移学习(如 ResNet/EfficientNet)建立基线。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:handm.csv。
This dataset contains a rich and structured catalog of H&M products scraped directly from their official website. It includes detailed metadata for each product such as:
Product ID, Name, and Brand
Product URL and Price
Stock Availability and Coming Soon Flag
Color Name, Available Color Variants, and Color Shades
常见问题
H&M 报废产品数据集是什么?
该数据集《H&M Scrapped Product Dataset》主要用于监督学习任务,数据形态以图像为主,应用场景偏向环保分类。
H&M 报废产品数据集是什么数据格式?坐标系是什么?
数据格式为 CSV。
H&M 报废产品数据集是如何生产或处理的?
This dataset contains a rich and structured catalog of H&M products scraped directly from their official website.
如何获取并引用H&M 报废产品数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. H&M 报废产品数据集. https://www.gis5g.com/dataset/2033810584968269825