地球资源数据云——数据资源详情
马拉雅拉姆语-英语 NLP
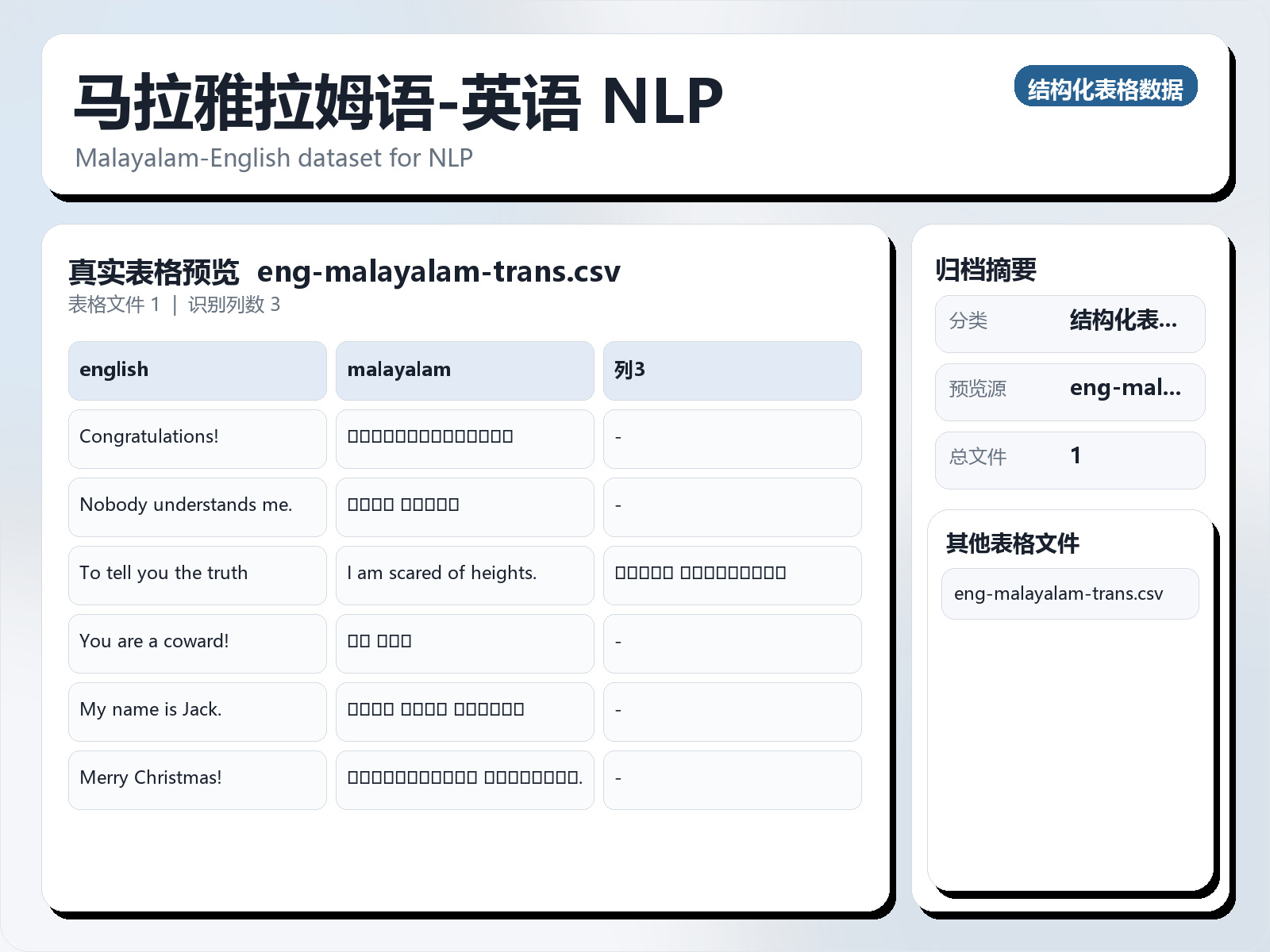
该数据集《Malayalam - English NLP》主要用于监督学习任务,数据形态以文本为主。 题目说明:Malayalam - English dataset for NLP 任务类型:文本监督学习。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:eng - malayalam - trans.csv。 Dataset Description: English - Malayalam Language Translation Overview This dataset contains parallel text data for language translation between English and Malayalam. The data is sourced from two major resources: Orpus and Tatoeba. The dataset is primarily intended for training machine learning models for English - Malayalam translation tasks. Each entry in the dataset consists of two rows: one for English sentences and the corresponding translation in Malayalam. Data Format The dataset is provided in CSV format with two columns:
摘要概览
该数据集《Malayalam - English NLP》主要用于监督学习任务,数据形态以文本为主。 题目说明:Malayalam - English dataset for NLP
任务类型:文本监督学习。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:eng - malayalam - trans.csv。
Dataset Description: English - Malayalam Language Translation
Overview
This dataset contains parallel text data for language translation between English and Malayalam. The data is sourced from two major resources: Orpus and Tatoeba. The dataset is primarily intended for training machine learning models for English - Malayalam translation tasks.
Each entry in the dataset consists of two rows: one for English sentences and the corresponding translation in Malayalam.
Data Format The dataset is provided in CSV format with two columns:
常见问题
马拉雅拉姆语-英语 NLP是什么?
该数据集《Malayalam - English NLP》主要用于监督学习任务,数据形态以文本为主。
马拉雅拉姆语-英语 NLP是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用马拉雅拉姆语-英语 NLP?
在本页登录后即可下载。建议引用格式:地球资源数据云. 马拉雅拉姆语-英语 NLP. https://www.gis5g.com/dataset/2032009705550155777