地球资源数据云——数据资源详情
泰米尔英语文本中的情感分析
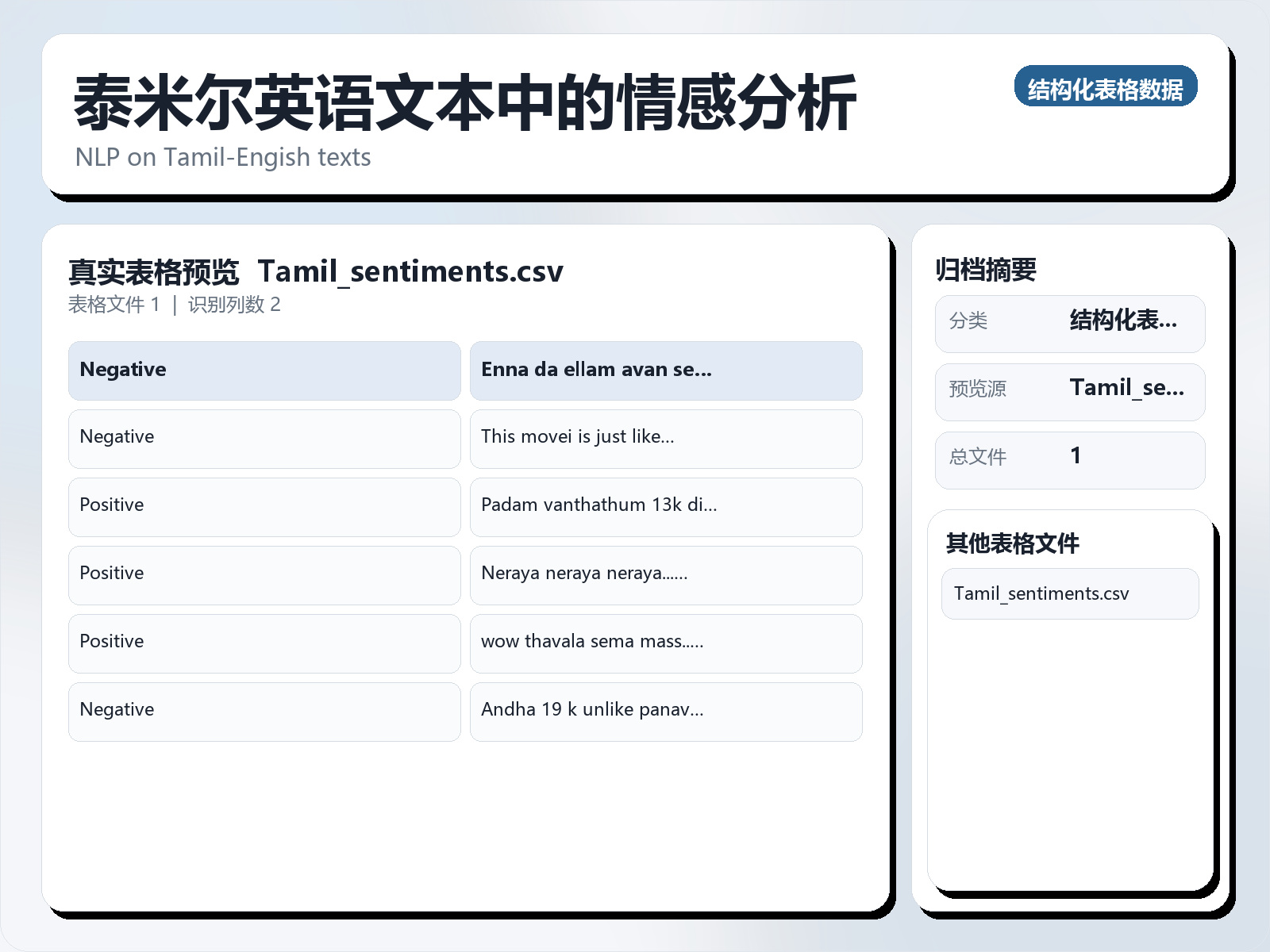
该数据集《Sentiment Analysis in Tamil - English Text》主要用于二分类任务,数据形态以图像为主,应用场景偏向文本内容分析。 题目说明:NLP on Tamil - Engish texts 任务类型:图像二分类。 建议流程:先检查类别分布与脏样本,再用迁移学习(如 ResNet/EfficientNet)建立基线。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:Tamil_sentiments.csv。 Content Understanding the sentiment of a comment from a video or an image is an essential task in many applications. Sentiment analysis of a text can be helpful in various decision - making processes. One such application is to analyze the popular sentiments of videos on social media based on viewer comments. However, comments from social media do not follow strict rules of grammar, and they contain a mixture of more than one language, often written in non - native scripts. Non - availability of annotated code - mixed data for a low - resourced language like Tamil also adds difficulty to this problem. To overcome this, we created a gold standard Tamil - English code - switched, sentiment - annotated corpus containing 15,744 comment posts from YouTube. This paper describes the process of creating the corpus and assigning polarities. We present inter - annotator agreement and show the results of sentiment analyses trained on this corpus as a benchmark. This dataset consists of two classes +ve and - ve comments in Tamil - English which means Tamil words in English alphabets.
摘要概览
该数据集《Sentiment Analysis in Tamil - English Text》主要用于二分类任务,数据形态以图像为主,应用场景偏向文本内容分析。 题目说明:NLP on Tamil - Engish texts
任务类型:图像二分类。
建议流程:先检查类别分布与脏样本,再用迁移学习(如 ResNet/EfficientNet)建立基线。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:Tamil_sentiments.csv。
Content
Understanding the sentiment of a comment from a video or an image is an essential task in many applications. Sentiment analysis of a text can be helpful in various decision - making processes. One such application is to analyze the popular sentiments of videos on social media based on viewer comments.
However, comments from social media do not follow strict rules of grammar, and they contain a mixture of more than one language, often written in non - native scripts. Non - availability of annotated code - mixed data for a low - resourced language like Tamil also adds difficulty to this problem.
To overcome this, we created a gold standard Tamil - English code - switched, sentiment - annotated corpus containing 15,744 comment posts from YouTube. This paper describes the process of creating the corpus and assigning polarities. We present inter - annotator agreement and show the results of sentiment analyses trained on this corpus as a benchmark.
This dataset consists of two classes +ve and - ve comments in Tamil - English which means Tamil words in English alphabets.
常见问题
泰米尔英语文本中的情感分析是什么?
该数据集《Sentiment Analysis in Tamil - English Text》主要用于二分类任务,数据形态以图像为主,应用场景偏向文本内容分析。
泰米尔英语文本中的情感分析是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用泰米尔英语文本中的情感分析?
在本页登录后即可下载。建议引用格式:地球资源数据云. 泰米尔英语文本中的情感分析. https://www.gis5g.com/dataset/2032010364173324290