地球资源数据云——数据资源详情
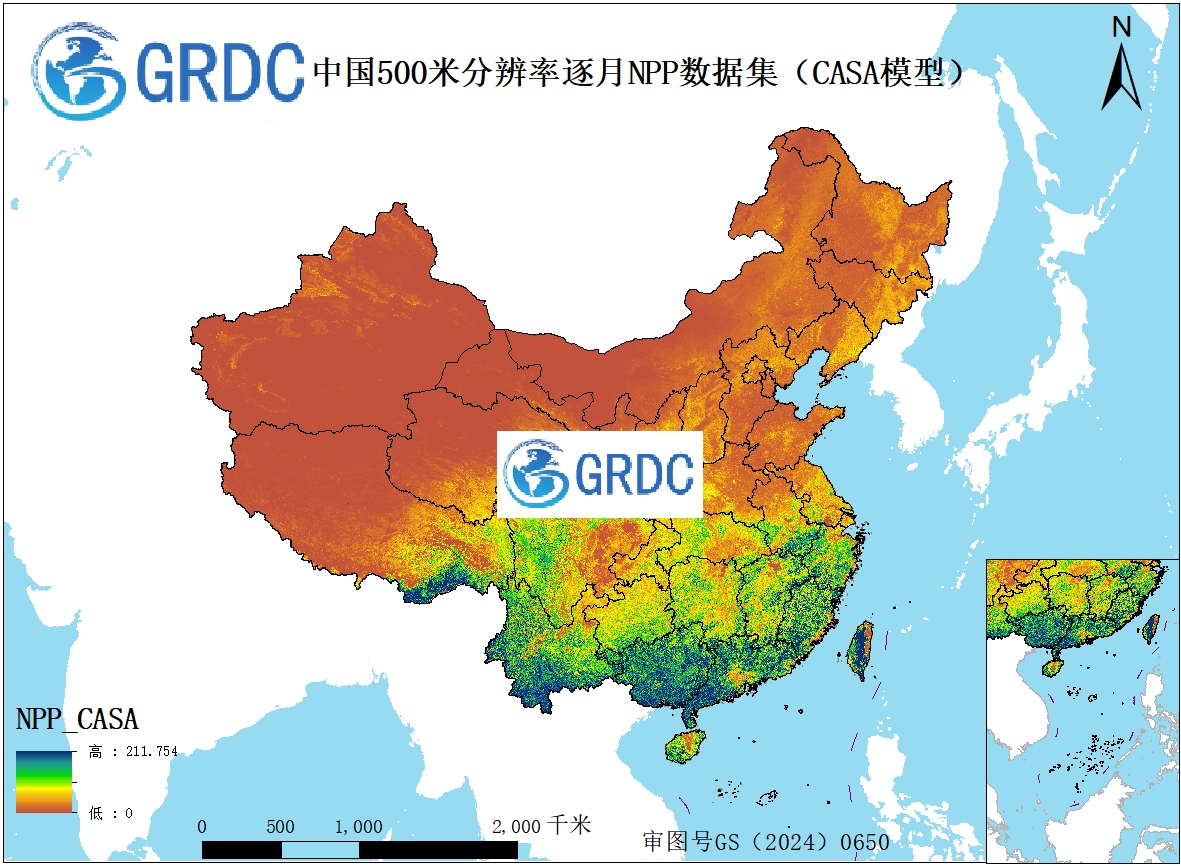
基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集
本数据集基于 CASA 模型构建,提供了 198 2 年至 2025 年中国区域 逐月 净初级生产力( NPP )数据,空间分辨率为 5 00 米。数据生产主要利用多源遥感数据(如 AVHRR 、 MODIS )与气象再分析数据驱动过程模型,通过光合有效辐射吸收比例与光能利用率原理估算植被年固碳量。数据集采用统一的算法框架与参数体系,确保了长时间序列的一致性。数据格式为 GeoTIFF ,采用 Albers 等面积圆锥投影,覆盖全国陆地范围。质量控制通过异常值剔除、与站点观测及已有产品交叉验证实现。该数据集为评估生态系统碳收支、研究植被对气候变化的响应及生态工程效益提供了长时间、高空间分辨率的基准数据,对陆地碳循环研究、环境政策制定具有重要支撑价值。 关键词 : 净初级生产力; NPP ; CASA 模型; 500 米分辨率 引 言 植被净初级生产力( Net Primary Productivity, NPP )是衡量生态系统碳汇能力与可持续性的关键指标,其精确估算对理解全球碳循环、评估气候变化影响及制定生态管理政策具有核心数据科学价值。传统的站点观测难以满足大尺度、连续监测的需求,而遥感与过程模型的融合为 NPP 的时空动态模拟提供了有效途径。先前研究已发展了诸如 CASA 、 GLOPEM 等经典模型,为本工作的开展奠定了方法论基础。本数据集基于 CASA 模型,整合了长时间序列的遥感与气象再分析数据,生成了 198 2 – 2025 年中国区域 5 00 米分辨率的 逐月 NPP 数据。该数据集有效弥补了现有产品在时空连续性或分辨率上的不足,其显著特点是覆盖时段长、空间分辨率高且算法一致性好。数据集经过严格的质量控制,包括与地面测量数据及已有权威产品的交叉验证,确保了可靠性。该数据可为评估中国陆地生态系统固碳现状、分析植被活动对气候波动的响应、以及量化重大生态工程的效益提供关键数据支撑,在气候变化研究、生态学和资源管理等领域具有广阔的重用潜力 。 1 数据采集和处理方法 1.1 数据采集方法 本数据集计算使用了归一化植被指数( NDVI ),土地利用,太阳辐射 , 降水,温度。分为预处理和计算两个部分,预处理部分主要通过裁剪,投影的方式统一数据的范围,行列数,投影,分辨率。计算部分通过公式分步计算。 本数据集 500 米分辨率的中国范围的净初级生产力( NPP )数据,及下方列举的生产所需的数据统一采用了墨卡托( UTM_Zone_46N )投影。 1.1.1 归一化植被指数数据( NDVI )数据 1982 - 1999 年数据来源于 NOAA CDR AVHRR NDVI 数据 ,分辨率为 5 KM 。 2000 - 2025 年数据来源于 MOD13A1 V6.1 版本, 此产品的算法会从 16 天内的所有采集中选择最佳可用像素值。所用标准为低云、低视角和最高 NDVI 值。 通过编写代码筛选时间范围进行最大值合成,并根据上传的中国区域范围进行裁剪,对裁剪好的影像进行导出下载。得到一年内逐月的最大值的 NDVI 的 TIFF 影像。 1.1.2 土地利用数据
摘要概览
本数据集基于 CASA 模型构建,提供了 198 2 年至 2025 年中国区域 逐月 净初级生产力( NPP )数据,空间分辨率为 5 00 米。数据生产主要利用多源遥感数据(如 AVHRR 、 MODIS )与气象再分析数据驱动过程模型,通过光合有效辐射吸收比例与光能利用率原理估算植被年固碳量。数据集采用统一的算法框架与参数体系,确保了长时间序列的一致性。数据格式为 GeoTIFF ,采用 Albers 等面积圆锥投影,覆盖全国陆地范围。质量控制通过异常值剔除、与站点观测及已有产品交叉验证实现。该数据集为评估生态系统碳收支、研究植被对气候变化的响应及生态工程效益提供了长时间、高空间分辨率的基准数据,对陆地碳循环研究、环境政策制定具有重要支撑价值。
关键词 : 净初级生产力; NPP ; CASA 模型; 500 米分辨率
引 言
植被净初级生产力( Net Primary Productivity, NPP )是衡量生态系统碳汇能力与可持续性的关键指标,其精确估算对理解全球碳循环、评估气候变化影响及制定生态管理政策具有核心数据科学价值。传统的站点观测难以满足大尺度、连续监测的需求,而遥感与过程模型的融合为 NPP 的时空动态模拟提供了有效途径。先前研究已发展了诸如 CASA 、 GLOPEM 等经典模型,为本工作的开展奠定了方法论基础。本数据集基于 CASA 模型,整合了长时间序列的遥感与气象再分析数据,生成了 198 2 – 2025 年中国区域 5 00 米分辨率的 逐月 NPP 数据。该数据集有效弥补了现有产品在时空连续性或分辨率上的不足,其显著特点是覆盖时段长、空间分辨率高且算法一致性好。数据集经过严格的质量控制,包括与地面测量数据及已有权威产品的交叉验证,确保了可靠性。该数据可为评估中国陆地生态系统固碳现状、分析植被活动对气候波动的响应、以及量化重大生态工程的效益提供关键数据支撑,在气候变化研究、生态学和资源管理等领域具有广阔的重用潜力 。
1 数据采集和处理方法
1.1 数据采集方法
本数据集计算使用了归一化植被指数( NDVI ),土地利用,太阳辐射 , 降水,温度。分为预处理和计算两个部分,预处理部分主要通过裁剪,投影的方式统一数据的范围,行列数,投影,分辨率。计算部分通过公式分步计算。 本数据集 500 米分辨率的中国范围的净初级生产力( NPP )数据,及下方列举的生产所需的数据统一采用了墨卡托( UTM_Zone_46N )投影。
1.1.1 归一化植被指数数据( NDVI )数据
1982 - 1999 年数据来源于 NOAA CDR AVHRR NDVI 数据 ,分辨率为 5 KM 。 2000 - 2025 年数据来源于 MOD13A1 V6.1 版本, 此产品的算法会从 16 天内的所有采集中选择最佳可用像素值。所用标准为低云、低视角和最高 NDVI 值。 通过编写代码筛选时间范围进行最大值合成,并根据上传的中国区域范围进行裁剪,对裁剪好的影像进行导出下载。得到一年内逐月的最大值的 NDVI 的 TIFF 影像。
1.1.2 土地利用数据
常见问题
基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集是什么?
本数据集基于 CASA 模型构建,提供了 198 2年至 2025年中国区域 逐月 净初级生产力(NPP)数据,空间分辨率为 5 00米。
基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集的数据来源是什么?
数据来源于NOAA CDR AVHRR NDVI 数据,由地球资源数据云整理发布。
基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集是什么数据格式?坐标系是什么?
数据格式为 GeoTIFF,坐标系为 墨卡托投影。
基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集的时间范围是什么?
数据时间跨度为 1982–1999年。
基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集的时间频率是什么?
该数据集时间尺度包含月尺度。
基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集的空间分辨率是多少?
该数据集空间分辨率为 500米。
基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集覆盖什么区域?
该数据集覆盖范围为全球。
如何获取并引用基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. 基于CASA模型的1982-2025年中国逐月500米分辨率NPP数据集. https://www.gis5g.com/dataset/2408