地球资源数据云——数据资源详情
SkyRatings:发布超过 23K 条航空公司评论!
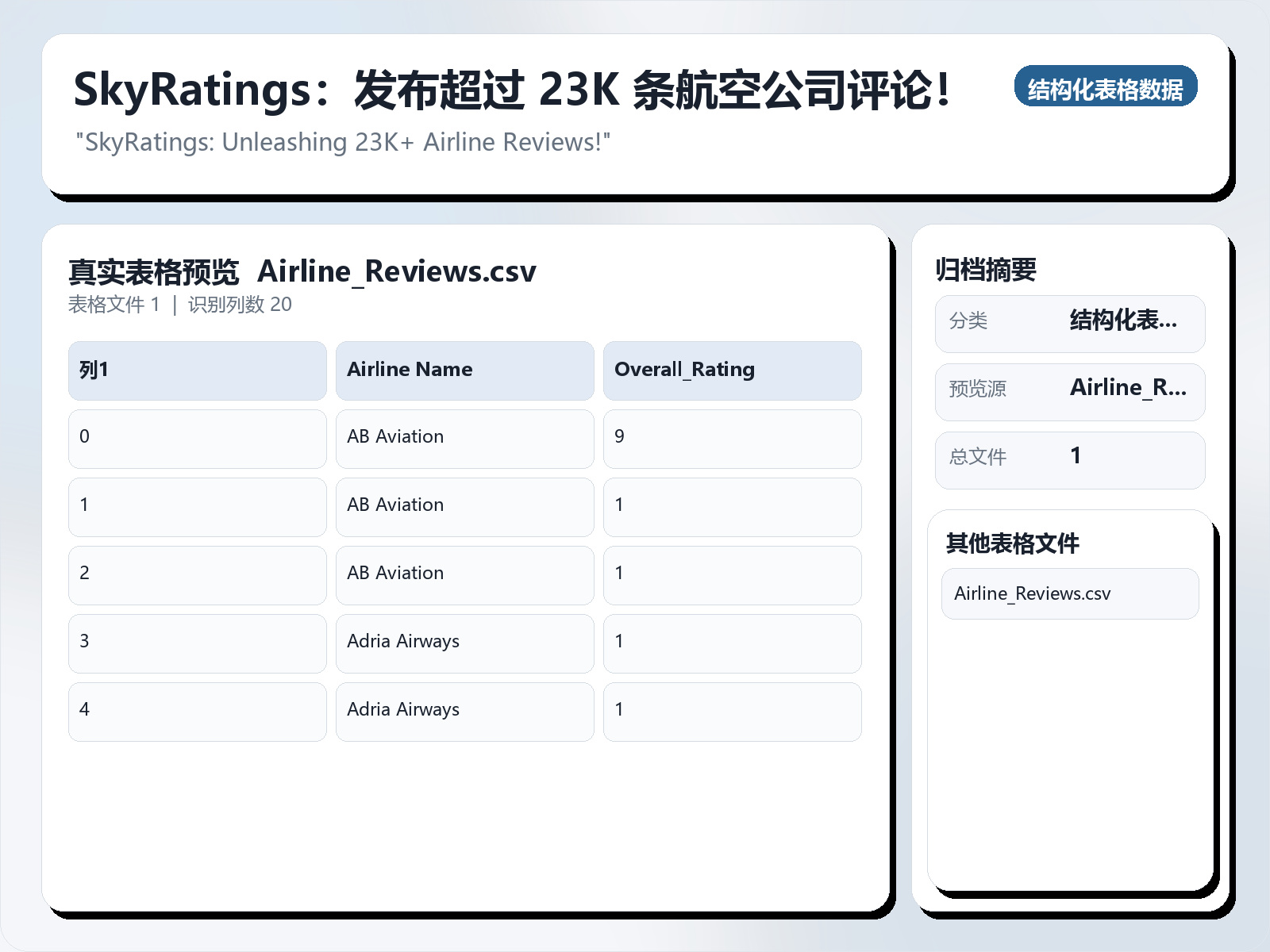
该数据集《SkyRatings: Unleashing 23K+ Airline Reviews!》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:"SkyRatings: Unleashing 23K+ Airline Reviews!" 任务类型:文本多分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:Airline_Reviews.csv。 The data for this airline reviews dataset was collected by web scraping the website https://www.airlinequality.com/ using the Python library Beautiful Soup. The website serves as a platform for travelers to submit their reviews and ratings about different airlines. By parsing the HTML content of the website, relevant information such as airline names, ratings, review titles, dates, and other attributes were extracted. The collected data was then processed and organized into a structured dataset, where each row represents a single airline review and each column represents a specific review attribute. Adherence to data privacy and website terms of use was ensured throughout the collection process. This transparent methodology allows others to understand the data's origin and how it was obtained, facilitating further analysis and research. Here's how I scrapped the data: https://www.kaggle.com/khushipitroda/airline - review - scrapping/ Task List for Data Analysis, Machine Learning, and NLP on Airline Reviews Dataset:
摘要概览
该数据集《SkyRatings: Unleashing 23K+ Airline Reviews!》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:"SkyRatings: Unleashing 23K+ Airline Reviews!"
任务类型:文本多分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:Airline_Reviews.csv。
The data for this airline reviews dataset was collected by web scraping the website https://www.airlinequality.com/ using the Python library Beautiful Soup. The website serves as a platform for travelers to submit their reviews and ratings about different airlines.
By parsing the HTML content of the website, relevant information such as airline names, ratings, review titles, dates, and other attributes were extracted. The collected data was then processed and organized into a structured dataset, where each row represents a single airline review and each column represents a specific review attribute.
Adherence to data privacy and website terms of use was ensured throughout the collection process. This transparent methodology allows others to understand the data's origin and how it was obtained, facilitating further analysis and research.
Here's how I scrapped the data: https://www.kaggle.com/khushipitroda/airline - review - scrapping/
Task List for Data Analysis, Machine Learning, and NLP on Airline Reviews Dataset:
常见问题
SkyRatings:发布超过 23K 条航空公司评论!是什么?
该数据集《SkyRatings: Unleashing 23K+ Airline Reviews!
SkyRatings:发布超过 23K 条航空公司评论!是什么数据格式?坐标系是什么?
数据格式为 CSV。
SkyRatings:发布超过 23K 条航空公司评论!是如何生产或处理的?
The data for this airline reviews dataset was collected by web scraping the website https://www.
SkyRatings:发布超过 23K 条航空公司评论!可以用于什么?
》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
如何获取并引用SkyRatings:发布超过 23K 条航空公司评论!?
在本页登录后即可下载。建议引用格式:地球资源数据云. SkyRatings:发布超过 23K 条航空公司评论!. https://www.gis5g.com/dataset/2033811002892914689