地球资源数据云——数据资源详情
IMBD 电影评论-NLP
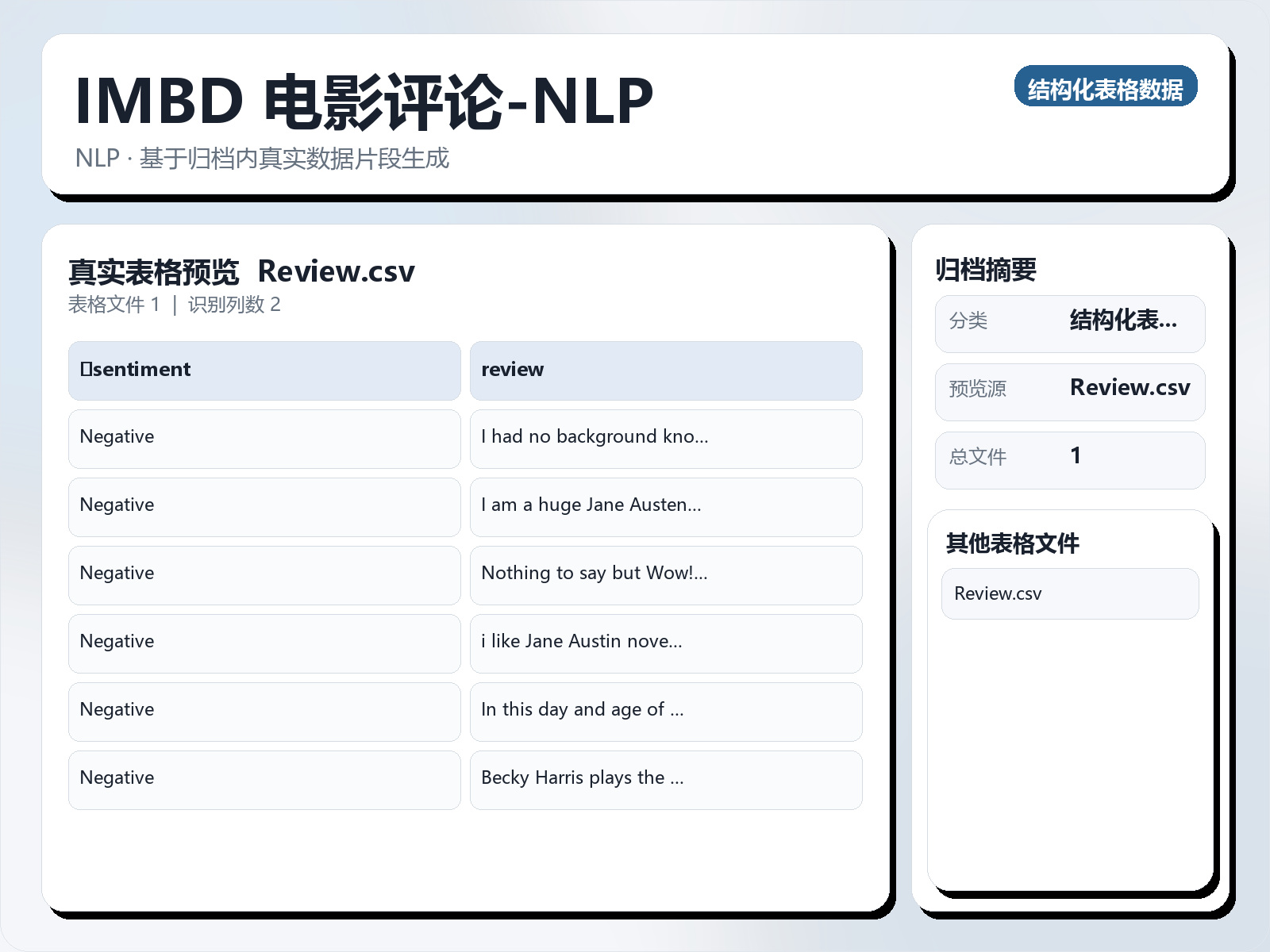
该数据集《IMBD Movie Review - NLP》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Data Set The labeled data set consists of 25,000 IMDB movie reviews, specially… 任务类型:文本二分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:Review.csv。 Data Set The labeled data set consists of 25,000 IMDB movie reviews, specially selected for sentiment analysis. The sentiment of reviews is binary, meaning the IMDB rating < 5 results in a sentiment score of "Negative", and rating >=7 have a sentiment score of "Positive." No individual movie has more than 30 reviews. File description MovieReviewTrainingDatabase.csv - The labeled training set. The file is comma - delimited and has a header row followed by 25,000 rows containing the sentiment and the text for each review. Data fields sentiment - Sentiment of the review; "Positive" for positive reviews and "Negative" for negative reviews review - Text of the review
摘要概览
该数据集《IMBD Movie Review - NLP》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Data Set The labeled data set consists of 25,000 IMDB movie reviews, specially…
任务类型:文本二分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:Review.csv。
Data Set The labeled data set consists of 25,000 IMDB movie reviews, specially selected for sentiment analysis. The sentiment of reviews is binary, meaning the IMDB rating < 5 results in a sentiment score of "Negative", and rating >=7 have a sentiment score of "Positive." No individual movie has more than 30 reviews.
File description MovieReviewTrainingDatabase.csv - The labeled training set. The file is comma - delimited and has a header row followed by 25,000 rows containing the sentiment and the text for each review.
Data fields sentiment - Sentiment of the review; "Positive" for positive reviews and "Negative" for negative reviews review - Text of the review
常见问题
IMBD 电影评论-NLP是什么?
该数据集《IMBD Movie Review - NLP》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
IMBD 电影评论-NLP是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用IMBD 电影评论-NLP?
在本页登录后即可下载。建议引用格式:地球资源数据云. IMBD 电影评论-NLP. https://www.gis5g.com/dataset/2033810703247642626