地球资源数据云——数据资源详情
AG新闻分类数据集
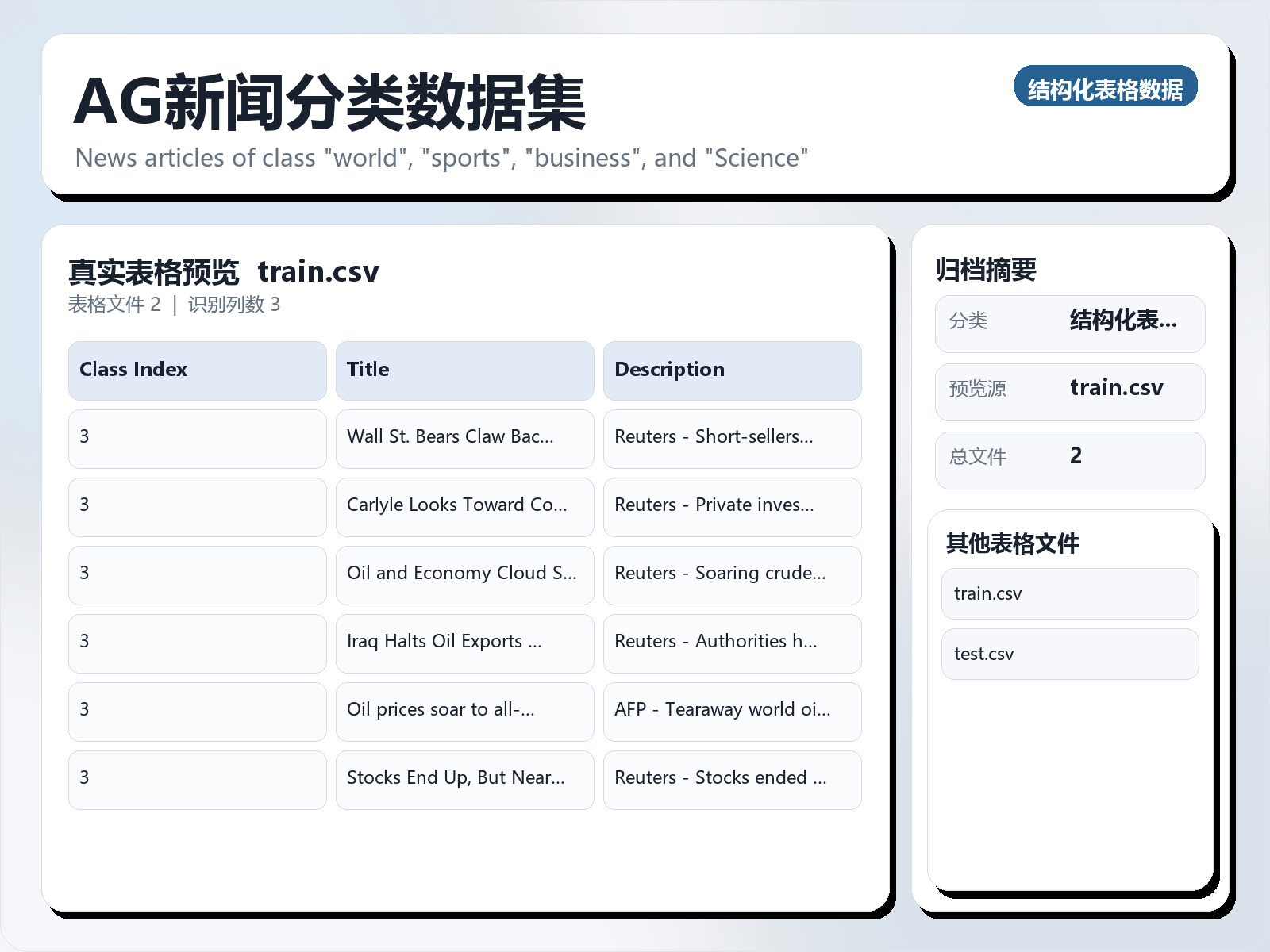
该数据集《AG News Classification Dataset》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:News articles of class "world", "sports", "business", and "Science" 任务类型:文本多分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:test.csv, train.csv。 AG's News Topic Classification Dataset ORIGIN AG is a collection of more than 1 million news articles. News articles have been gathered from more than 2000 news sources by ComeToMyHead in more than 1 year of activity. ComeToMyHead is an academic news search engine which has been running since July, 2004. The dataset is provided by the academic comunity for research purposes in data mining (clustering, classification, etc), information retrieval (ranking, search, etc), xml, data compression, data streaming, and any other non - commercial activity. For more information, please refer to the link http://www.di.unipi.it/~gulli/AG_corpus_of_news_articles.html . The AG's news topic classification dataset is constructed by Xiang Zhang (xiang.zhang@nyu.edu) from the dataset above. It is used as a text classification benchmark in the following paper: Xiang Zhang, Junbo Zhao, Yann LeCun. Character - level Convolutional Networks for Text Classification. Advances in Neural Information Processing Systems 28 (NIPS 2015).
摘要概览
该数据集《AG News Classification Dataset》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:News articles of class "world", "sports", "business", and "Science"
任务类型:文本多分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:test.csv, train.csv。
AG's News Topic Classification Dataset
ORIGIN
AG is a collection of more than 1 million news articles. News articles have been gathered from more than 2000 news sources by ComeToMyHead in more than 1 year of activity. ComeToMyHead is an academic news search engine which has been running since July, 2004.
The dataset is provided by the academic comunity for research purposes in data mining (clustering, classification, etc), information retrieval (ranking, search, etc), xml, data compression, data streaming, and any other non - commercial activity. For more information, please refer to the link http://www.di.unipi.it/~gulli/AG_corpus_of_news_articles.html .
The AG's news topic classification dataset is constructed by Xiang Zhang (xiang.zhang@nyu.edu) from the dataset above. It is used as a text classification benchmark in the following paper: Xiang Zhang, Junbo Zhao, Yann LeCun. Character - level Convolutional Networks for Text Classification. Advances in Neural Information Processing Systems 28 (NIPS 2015).
常见问题
AG新闻分类数据集是什么?
该数据集《AG News Classification Dataset》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
AG新闻分类数据集是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用AG新闻分类数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. AG新闻分类数据集. https://www.gis5g.com/dataset/2033809330711990273