地球资源数据云——数据资源详情
问答数据集
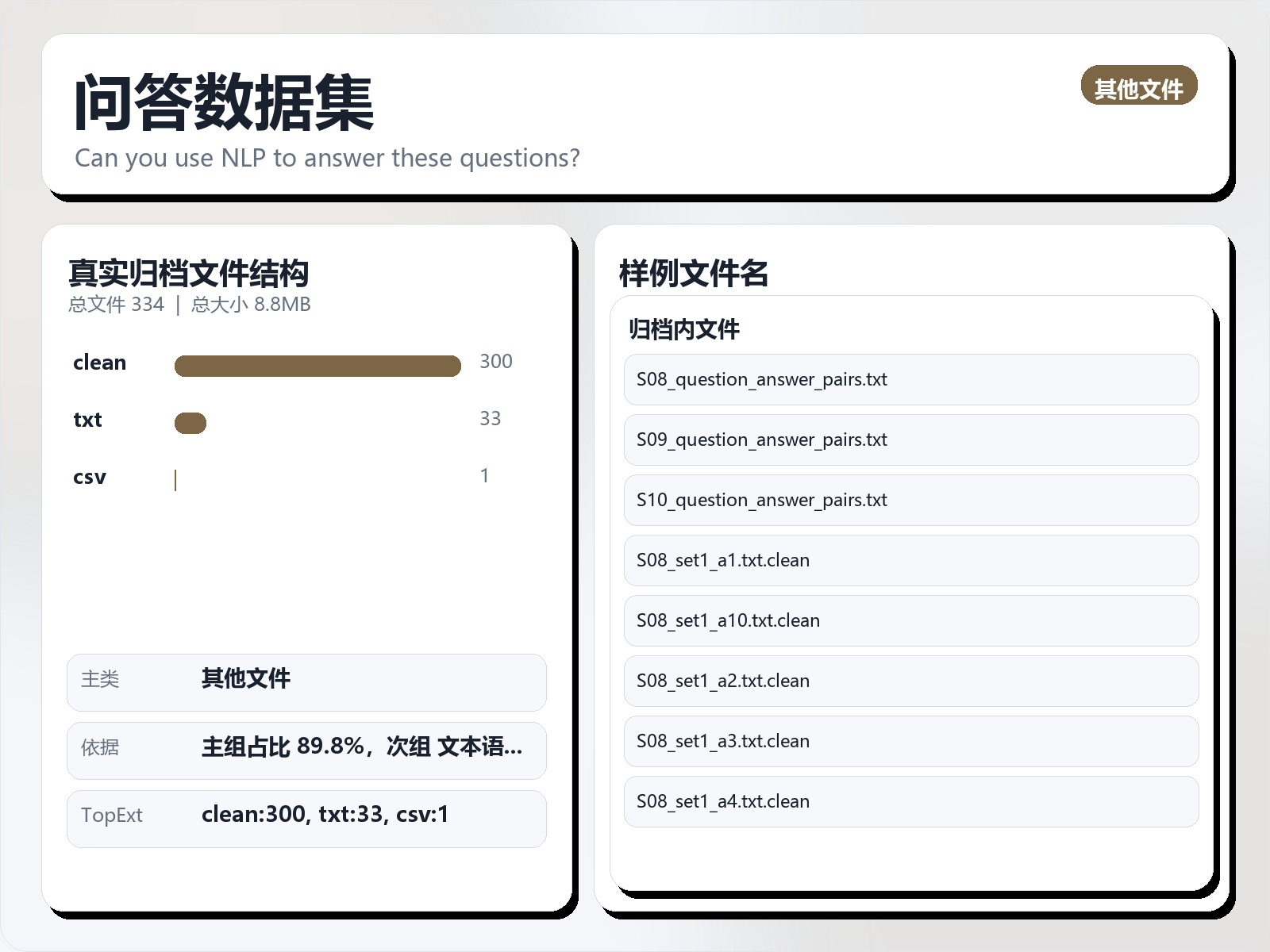
该数据集《Question - Answer Dataset》主要用于监督学习任务,数据形态以文本为主,应用场景偏向交通/汽车。 题目说明:Can you use NLP to answer these questions? 任务类型:文本监督学习。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:text_data_toc.csv。 Context: Being able to automatically answer questions accurately remains a difficult problem in natural language processing. This dataset has everything you need to try your own hand at this task. Can you correctly generate the answer to questions given the Wikipedia article text the question was originally generated from? Content: There are three question files, one for each year of students: S08, S09, and S10, as well as 690,000 words worth of cleaned text from Wikipedia that was used to generate the questions. The "question_answer_pairs.txt" files contain both the questions and answers. The columns in this file are as follows:
摘要概览
该数据集《Question - Answer Dataset》主要用于监督学习任务,数据形态以文本为主,应用场景偏向交通/汽车。 题目说明:Can you use NLP to answer these questions?
任务类型:文本监督学习。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:text_data_toc.csv。
Context:
Being able to automatically answer questions accurately remains a difficult problem in natural language processing. This dataset has everything you need to try your own hand at this task. Can you correctly generate the answer to questions given the Wikipedia article text the question was originally generated from?
Content:
There are three question files, one for each year of students: S08, S09, and S10, as well as 690,000 words worth of cleaned text from Wikipedia that was used to generate the questions.
The "question_answer_pairs.txt" files contain both the questions and answers. The columns in this file are as follows:
常见问题
问答数据集是什么?
该数据集《Question - Answer Dataset》主要用于监督学习任务,数据形态以文本为主,应用场景偏向交通/汽车。
问答数据集是什么数据格式?坐标系是什么?
数据格式为 CSV。
问答数据集是如何生产或处理的?
Can you correctly generate the answer to questions given the Wikipedia article text the question was originally generated from?
如何获取并引用问答数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. 问答数据集. https://www.gis5g.com/dataset/2033787458498760705