地球资源数据云——数据资源详情
2024 年 YouTube 订阅者数据
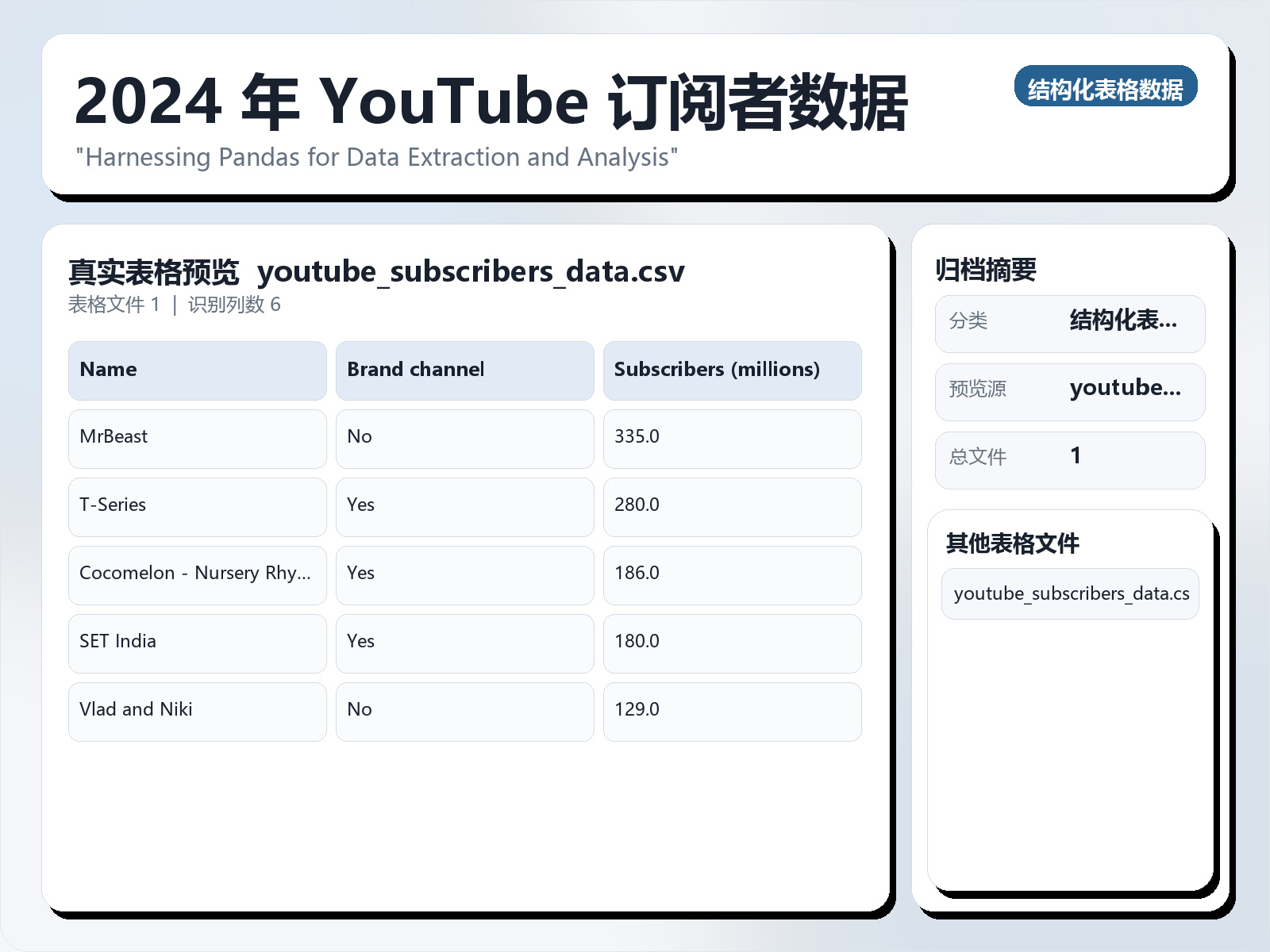
该数据集《Youtube Subscribers Data 2024》主要用于监督学习任务,数据形态以表格为主,应用场景偏向文本内容分析。 题目说明:"Harnessing Pandas for Data Extraction and Analysis" 任务类型:表格监督学习。 建议流程:先做缺失值/异常值处理与特征编码,再比较逻辑回归、随机森林、XGBoost。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:youtube_subscribers_data.csv。 In this dataset, we aim to extract, clean, and analyze subscriber statistics from YouTube channels using Python's pandas library. The primary objective is to create a comprehensive dataset that reflects the latest trends in YouTube subscriber counts, enabling further analysis and insights into the platform's most popular content creators. Objectives: Data Extraction: Utilize the pd.read_html function to scrape subscriber data from a reliable online source, specifically focusing on the Wikipedia page listing the most - subscribed YouTube channels. Data Cleaning: Perform necessary data cleaning operations to ensure the dataset is accurate and usable. This includes handling null values, converting data types, and removing any irrelevant columns. Data Export: Save the cleaned dataset as a CSV file for easy access and sharing. The dataset will be named in a search - friendly manner to enhance discoverability.
摘要概览
该数据集《Youtube Subscribers Data 2024》主要用于监督学习任务,数据形态以表格为主,应用场景偏向文本内容分析。 题目说明:"Harnessing Pandas for Data Extraction and Analysis"
任务类型:表格监督学习。
建议流程:先做缺失值/异常值处理与特征编码,再比较逻辑回归、随机森林、XGBoost。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:youtube_subscribers_data.csv。
In this dataset, we aim to extract, clean, and analyze subscriber statistics from YouTube channels using Python's pandas library. The primary objective is to create a comprehensive dataset that reflects the latest trends in YouTube subscriber counts, enabling further analysis and insights into the platform's most popular content creators.
Objectives:
Data Extraction: Utilize the pd.read_html function to scrape subscriber data from a reliable online source, specifically focusing on the Wikipedia page listing the most - subscribed YouTube channels.
Data Cleaning: Perform necessary data cleaning operations to ensure the dataset is accurate and usable. This includes handling null values, converting data types, and removing any irrelevant columns.
Data Export: Save the cleaned dataset as a CSV file for easy access and sharing. The dataset will be named in a search - friendly manner to enhance discoverability.
常见问题
2024 年 YouTube 订阅者数据是什么?
该数据集《Youtube Subscribers Data 2024》主要用于监督学习任务,数据形态以表格为主,应用场景偏向文本内容分析。
2024 年 YouTube 订阅者数据是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用2024 年 YouTube 订阅者数据?
在本页登录后即可下载。建议引用格式:地球资源数据云. 2024 年 YouTube 订阅者数据. https://www.gis5g.com/dataset/2032013088692539393