地球资源数据云——数据资源详情
股市推文 NLP
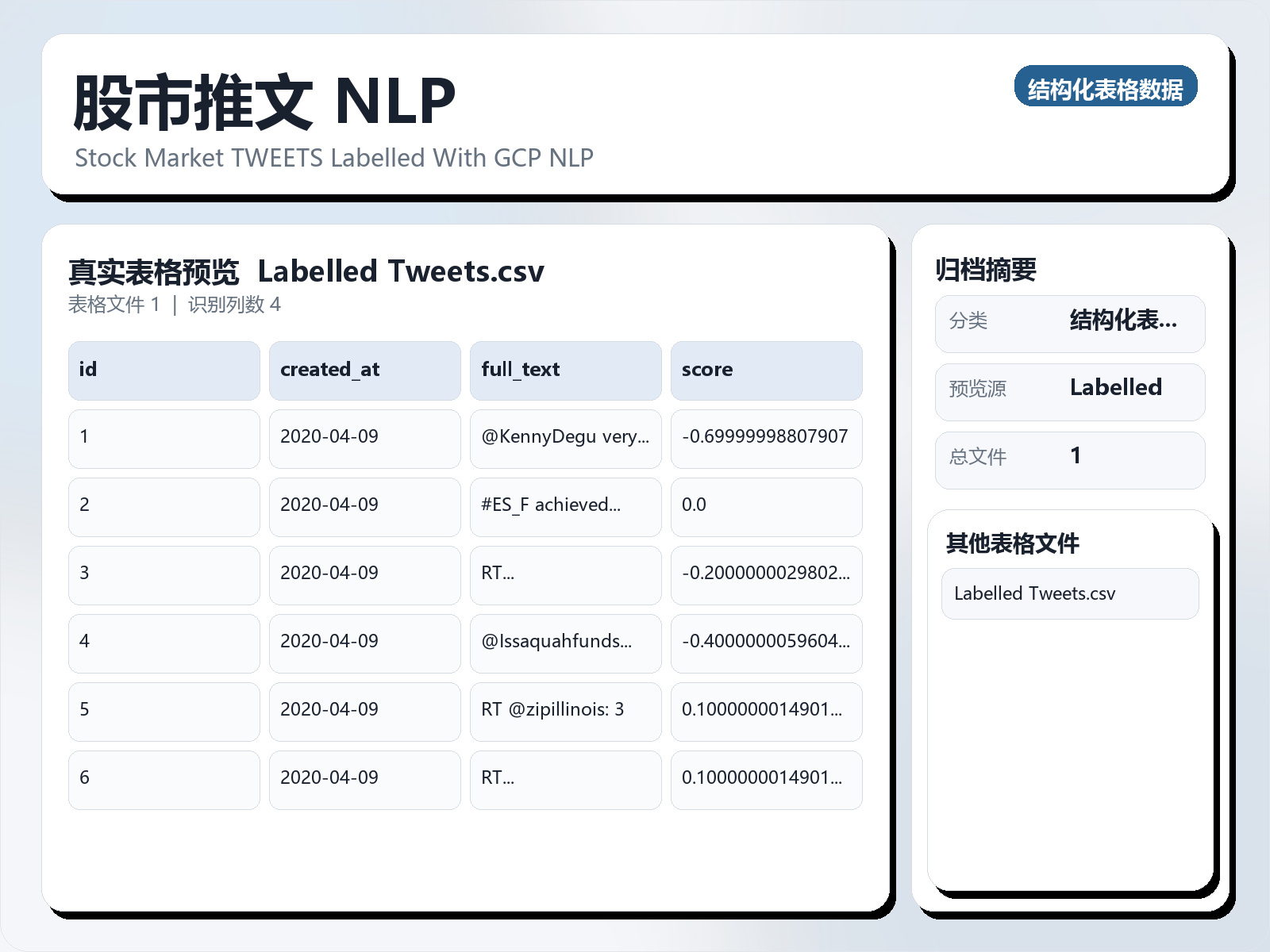
该数据集《Stock Market TWEETS NLP》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Stock Market TWEETS Labelled With GCP NLP 任务类型:文本多分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:Labelled Tweets.csv。 Context: Stock Market TWEETS Sentiment Analysis Data Set Overview: This is a data set of tweets related to the stock market. Dataset is derived from an existing dataset Stock Market TWEETS Data - NLP - 2021. In the original data set 943,9672 tweets are collected between April 9 and July 16, 2020, using the S&P 500 tag (#SPX500), the references to the top 25 companies in the S&P 500 index, and the Bloomberg tag (#stocks), However, In the original dataset, a total of 943,672 tweets are provided out of which only 1300 are labeled with the sentiment score which is a very small percentage.
摘要概览
该数据集《Stock Market TWEETS NLP》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Stock Market TWEETS Labelled With GCP NLP
任务类型:文本多分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:Labelled Tweets.csv。
Context:
Stock Market TWEETS Sentiment Analysis
Data Set Overview:
This is a data set of tweets related to the stock market. Dataset is derived from an existing dataset Stock Market TWEETS Data - NLP - 2021.
In the original data set 943,9672 tweets are collected between April 9 and July 16, 2020, using the S&P 500 tag (#SPX500), the references to the top 25 companies in the S&P 500 index, and the Bloomberg tag (#stocks), However, In the original dataset, a total of 943,672 tweets are provided out of which only 1300 are labeled with the sentiment score which is a very small percentage.
常见问题
股市推文 NLP是什么?
该数据集《Stock Market TWEETS NLP》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
股市推文 NLP是什么数据格式?坐标系是什么?
数据格式为 CSV。
股市推文 NLP是如何生产或处理的?
Dataset is derived from an existing dataset Stock Market TWEETS Data - NLP - 2021.
如何获取并引用股市推文 NLP?
在本页登录后即可下载。建议引用格式:地球资源数据云. 股市推文 NLP. https://www.gis5g.com/dataset/2032010427700252674