地球资源数据云——数据资源详情
Twitter、Reddit 和 YouTube 情绪数据集 2026
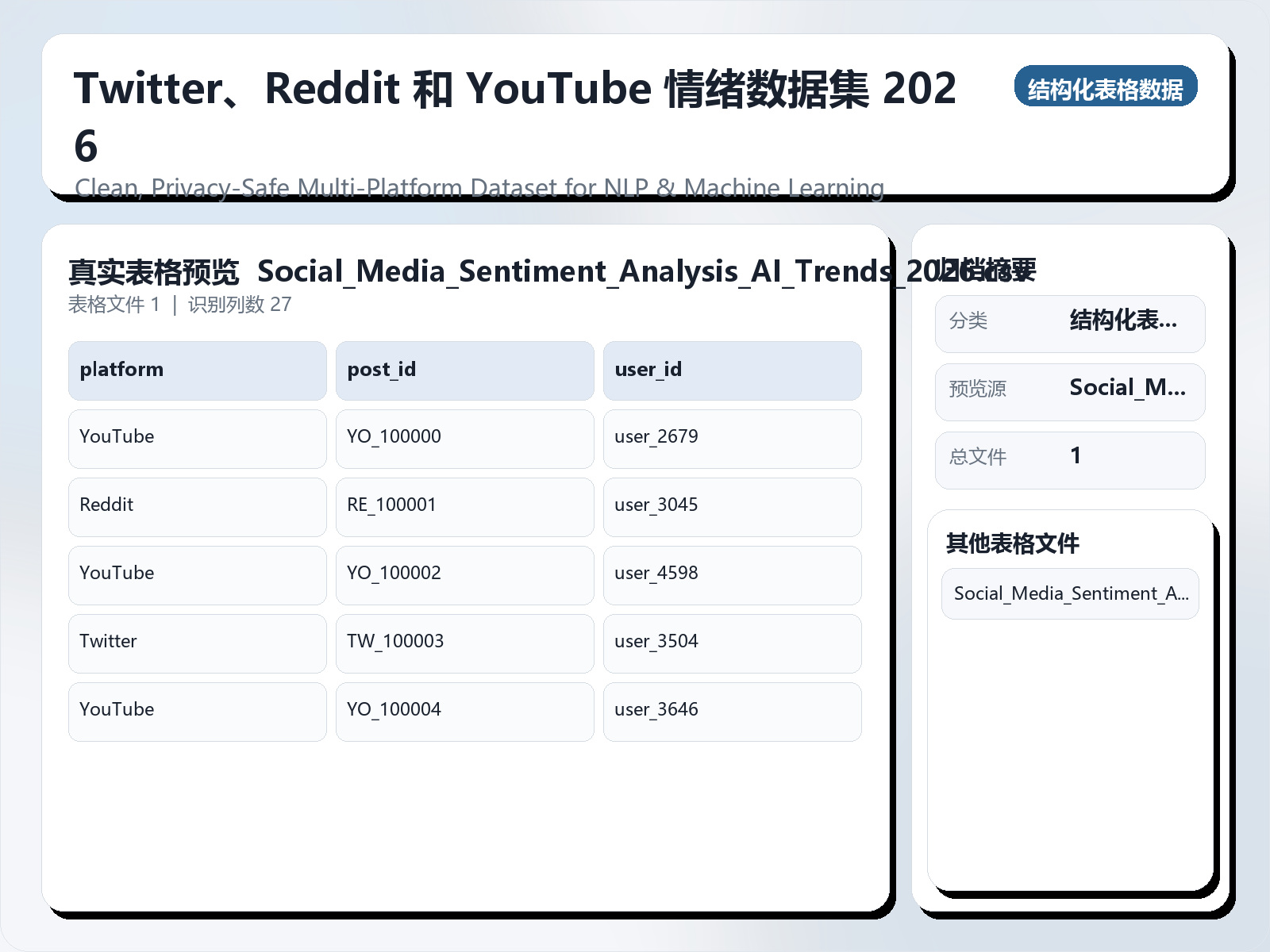
该数据集《Twitter, Reddit & YouTube Sentiment Dataset 2026》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Clean, Privacy - Safe Multi - Platform Dataset for NLP & Machine Learning 任务类型:文本二分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:Social_Media_Sentiment_Analysis_AI_Trends_2026.csv。 背景:Twitter (X)、Reddit 和 YouTube 等社交媒体平台每天都会生成大量用户生成的内容。分析这些数据可以帮助研究人员、数据科学家和企业实时了解公众舆论、情绪、趋势和在线行为。该数据集专为情感分析、情绪检测、毒性分析和趋势预测任务而设计。它模拟真实的社交媒体交互,同时通过使用合成生成的类人内容来保护用户隐私。该数据集反映了现代社交媒体模式,包括参与度指标、热门话题、情绪极性、情绪基调和垃圾邮件/毒性指标。它适用于 NLP、机器学习、深度学习和数据可视化项目,特别是 2026 年及以后的 Kaggle 竞赛和作品集。栏目描述 |栏目名称 |描述 | | - - - - - - - - - - - - - - - - - - - - | - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - | |平台|帖子/评论出现的社交媒体平台(Twitter、Reddit、YouTube)| |帖子 ID |每个帖子或评论的唯一标识符 | |用户 ID |用户的唯一(合成)标识符 | |用户名 |人工生成的用户名 | |用户验证 |指示用户是否已验证 | |用户关注者计数 |用户拥有的关注者数量 | |用户位置 |报告的用户位置 | |帖子文本 |帖子或评论的文字内容 | |语言 |语言代码
摘要概览
该数据集《Twitter, Reddit & YouTube Sentiment Dataset 2026》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Clean, Privacy - Safe Multi - Platform Dataset for NLP & Machine Learning
任务类型:文本二分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:Social_Media_Sentiment_Analysis_AI_Trends_2026.csv。
背景:Twitter (X)、Reddit 和 YouTube 等社交媒体平台每天都会生成大量用户生成的内容。分析这些数据可以帮助研究人员、数据科学家和企业实时了解公众舆论、情绪、趋势和在线行为。该数据集专为情感分析、情绪检测、毒性分析和趋势预测任务而设计。它模拟真实的社交媒体交互,同时通过使用合成生成的类人内容来保护用户隐私。该数据集反映了现代社交媒体模式,包括参与度指标、热门话题、情绪极性、情绪基调和垃圾邮件/毒性指标。它适用于 NLP、机器学习、深度学习和数据可视化项目,特别是 2026 年及以后的 Kaggle 竞赛和作品集。栏目描述 |栏目名称 |描述 | | - - - - - - - - - - - - - - - - - - - - | - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - | |平台|帖子/评论出现的社交媒体平台(Twitter、Reddit、YouTube)| |帖子 ID |每个帖子或评论的唯一标识符 | |用户 ID |用户的唯一(合成)标识符 | |用户名 |人工生成的用户名 | |用户验证 |指示用户是否已验证 | |用户关注者计数 |用户拥有的关注者数量 | |用户位置 |报告的用户位置 | |帖子文本 |帖子或评论的文字内容 | |语言 |语言代码
常见问题
Twitter、Reddit 和 YouTube 情绪数据集 2026是什么?
该数据集《Twitter, Reddit & YouTube Sentiment Dataset 2026》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
Twitter、Reddit 和 YouTube 情绪数据集 2026是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用Twitter、Reddit 和 YouTube 情绪数据集 2026?
在本页登录后即可下载。建议引用格式:地球资源数据云. Twitter、Reddit 和 YouTube 情绪数据集 2026. https://www.gis5g.com/dataset/2032008493475991554