地球资源数据云——数据资源详情
推特 SpaceX
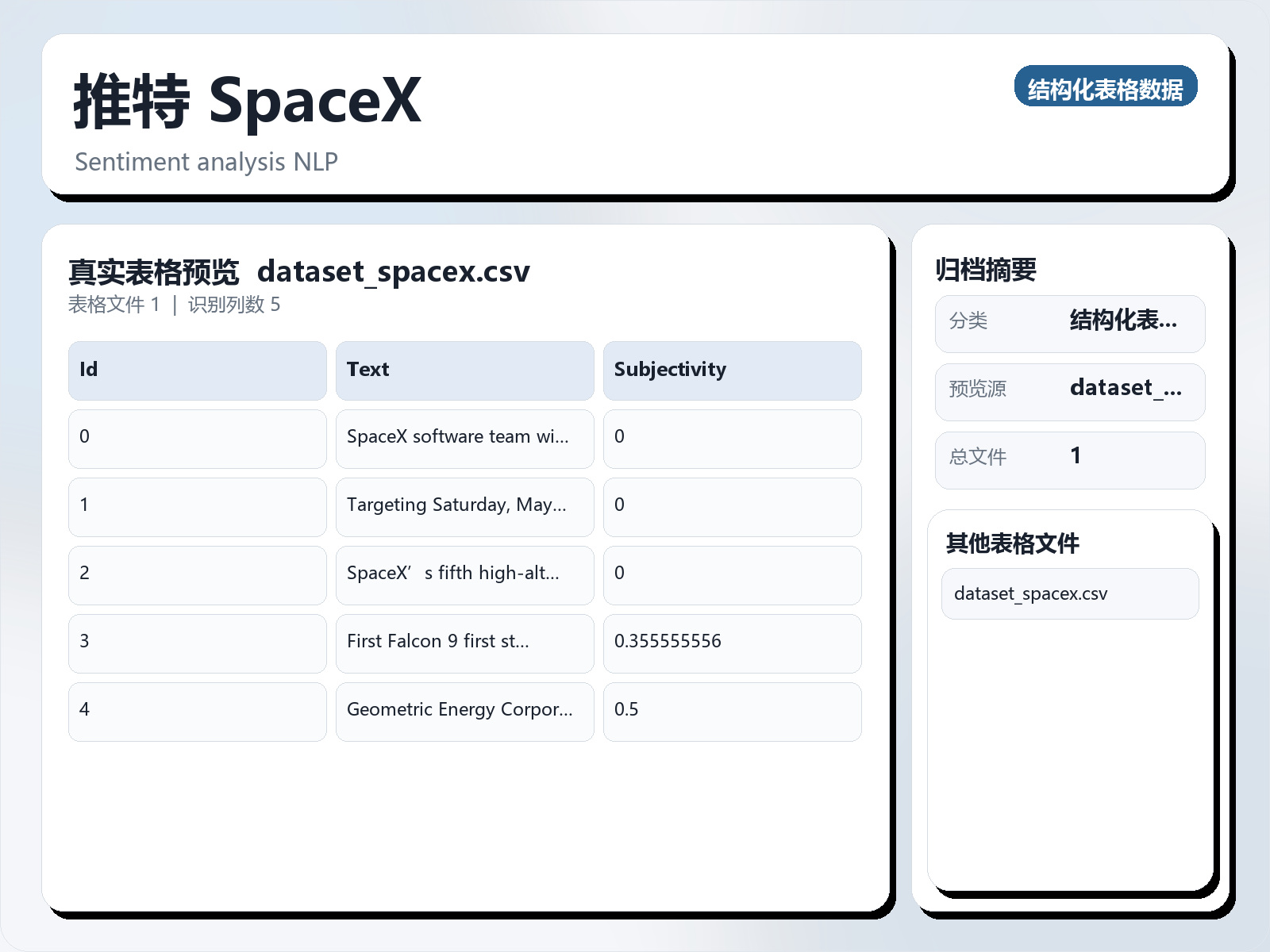
该数据集《Twitter Spacex》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Sentiment analysis NLP 任务类型:文本多分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:dataset_spacex.csv。 关于此数据集此数据集是使用 Twitter API 收集的,重点关注与特定主题或关键字相关的推文。它包括情感分析功能,可以深入了解每条推文的主观性质和情感极性。该数据集可用于情感分析、主题建模和社交媒体趋势分析。数据集文件: - tweets_data.csv:此文件包含收集的所有推文,以及情绪分析分数和其他元数据。 ### 列描述符: - Id: - 描述:数据集中每条推文的唯一数字标识符。 - 类型:整数 - 示例:123456789 - 文本: - 描述:推文的全文内容。每条推文不得超过 280 个字符。 - 类型:字符串 - 示例:“很高兴看到可再生能源的未来!#Sustainability #GreenEnergy” - 主观性: - 描述:0 到 1 之间的浮点分数,表示推文的主观程度。 0 分表示该推文完全客观(基于事实),而 1 分表示该推文完全主观(基于观点)。 - 类型:浮点数 - 范围:0(完全客观)到 1(完全主观) - 示例:0.75 - 极性: - 描述: - 1 到 1 之间的浮点分数,反映推文的情绪。 - 1 代表负面情绪,0 代表中性情绪,1 代表正面情绪。 - 类型:浮点数 - 范围: - 1(负)到 1(正) - 示例:0.5 - 目标: - 描述:推文正在讨论或引用的特定实体、关键字或主题。 - 类型:字符串 - 示例:“可再生能源” 出处:数据是使用官方 Twitter API 收集的。使用特定的关键字和主题标签来过滤选定时间段内的相关推文。数据收集完毕后,进行情感分析
摘要概览
该数据集《Twitter Spacex》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Sentiment analysis NLP
任务类型:文本多分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:dataset_spacex.csv。
关于此数据集此数据集是使用 Twitter API 收集的,重点关注与特定主题或关键字相关的推文。它包括情感分析功能,可以深入了解每条推文的主观性质和情感极性。该数据集可用于情感分析、主题建模和社交媒体趋势分析。数据集文件: - tweets_data.csv:此文件包含收集的所有推文,以及情绪分析分数和其他元数据。 ### 列描述符: - Id: - 描述:数据集中每条推文的唯一数字标识符。 - 类型:整数 - 示例:123456789 - 文本: - 描述:推文的全文内容。每条推文不得超过 280 个字符。 - 类型:字符串 - 示例:“很高兴看到可再生能源的未来!#Sustainability #GreenEnergy” - 主观性: - 描述:0 到 1 之间的浮点分数,表示推文的主观程度。 0 分表示该推文完全客观(基于事实),而 1 分表示该推文完全主观(基于观点)。 - 类型:浮点数 - 范围:0(完全客观)到 1(完全主观) - 示例:0.75 - 极性: - 描述: - 1 到 1 之间的浮点分数,反映推文的情绪。 - 1 代表负面情绪,0 代表中性情绪,1 代表正面情绪。 - 类型:浮点数 - 范围: - 1(负)到 1(正) - 示例:0.5 - 目标: - 描述:推文正在讨论或引用的特定实体、关键字或主题。 - 类型:字符串 - 示例:“可再生能源” 出处:数据是使用官方 Twitter API 收集的。使用特定的关键字和主题标签来过滤选定时间段内的相关推文。数据收集完毕后,进行情感分析
常见问题
推特 SpaceX是什么?
该数据集《Twitter Spacex》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
推特 SpaceX是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用推特 SpaceX?
在本页登录后即可下载。建议引用格式:地球资源数据云. 推特 SpaceX. https://www.gis5g.com/dataset/2032007342730940417