地球资源数据云——数据资源详情
辉瑞 (Pfizer) - AntiCovid
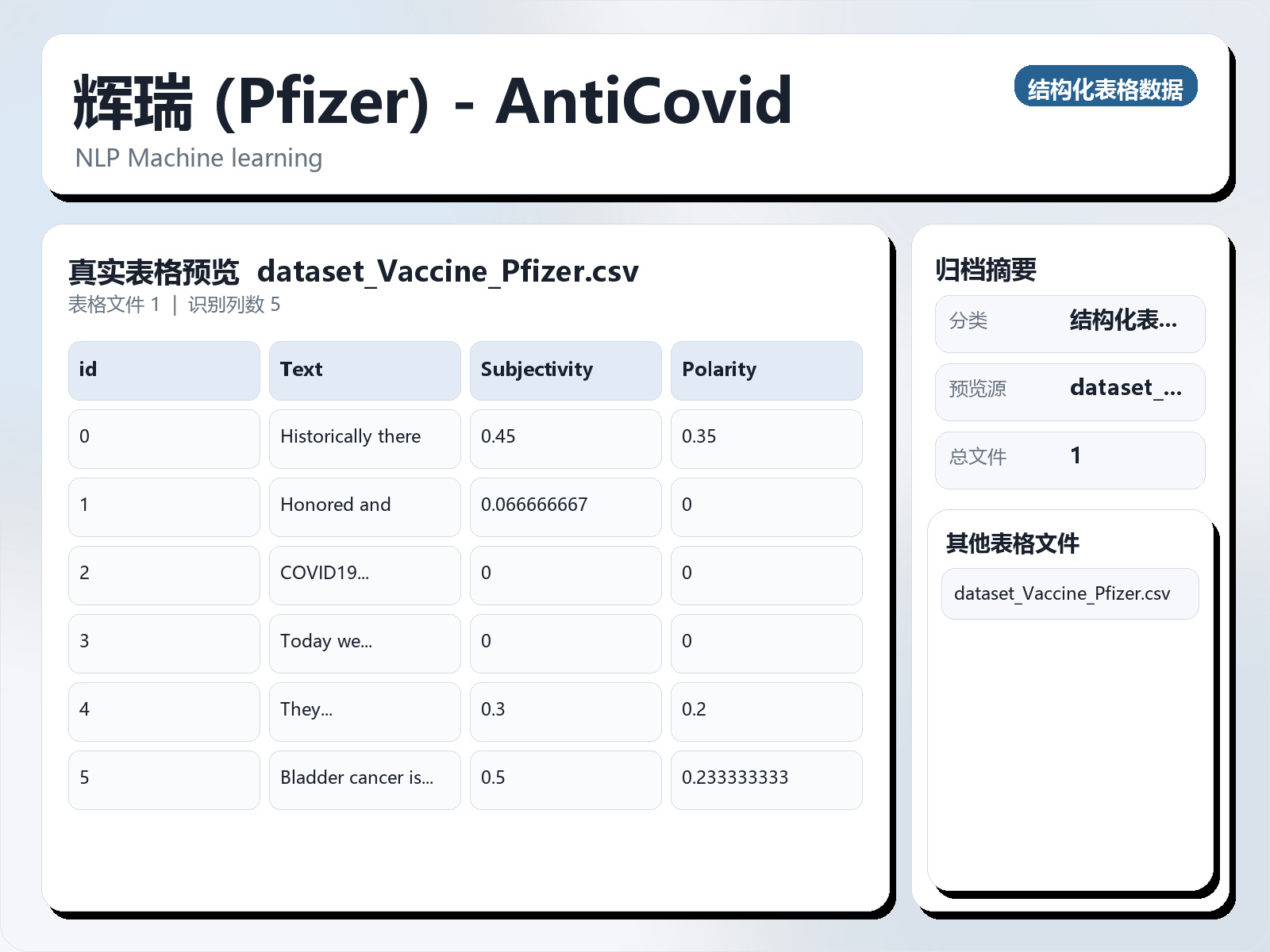
该数据集《Twitter Pfizer - AntiCovid》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:NLP Machine learning 任务类型:文本二分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:dataset_Vaccine_Pfizer.csv。 Twitter 辉瑞 - AntiCovid 数据集描述 该数据集包含从 Twitter 收集的有关辉瑞 COVID - 19 疫苗的推文。该数据集的主要目标是帮助研究人员、数据科学家和分析师了解公众对辉瑞疫苗的看法。它的结构支持情感分析、主观性分析和分类任务。列说明 1. id: - 说明:每条推文的唯一标识符。 - 类型:整数。 - 目的:用于唯一识别和区分数据集中的每条推文。 2. 文本: - 描述:文本形式的推文内容。 - 类型:字符串。 - 目的:提供每条推文的实际内容。该专栏可用于各种自然语言处理(NLP)任务,例如情感分析、关键词提取和主题建模。 3. 主观性: - 描述:0 到 1 之间的分数,代表推文的主观程度。 0 分表示该推文是客观的,而 1 分表示该推文非常主观。 - 类型:浮点型(范围:0 到 1)。 - 目的:表明推文中有多少内容是基于个人观点与事实信息。这对于识别更受观点驱动的推文非常有用。 4. 极性: - 描述:情绪极性得分,范围从 - 1(极度负面)到 1(极度正面)。 - 类型:浮点型(范围: - 1 到 1)。 - 目的:用于确定推文的情绪基调,无论是消极、中性还是积极。本专栏是情感分析任务的关键。 5. 目标: - 描述:一个二进制变量,表示推文对辉瑞疫苗的整体情绪。值为 0 表示负面情绪,值为 1 表示正面情绪。 - 类型:整数(0 或 1)。 - 目的:作为机器学习的目标标签
摘要概览
该数据集《Twitter Pfizer - AntiCovid》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:NLP Machine learning
任务类型:文本二分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:dataset_Vaccine_Pfizer.csv。
Twitter 辉瑞 - AntiCovid 数据集描述 该数据集包含从 Twitter 收集的有关辉瑞 COVID - 19 疫苗的推文。该数据集的主要目标是帮助研究人员、数据科学家和分析师了解公众对辉瑞疫苗的看法。它的结构支持情感分析、主观性分析和分类任务。列说明 1. id: - 说明:每条推文的唯一标识符。 - 类型:整数。 - 目的:用于唯一识别和区分数据集中的每条推文。 2. 文本: - 描述:文本形式的推文内容。 - 类型:字符串。 - 目的:提供每条推文的实际内容。该专栏可用于各种自然语言处理(NLP)任务,例如情感分析、关键词提取和主题建模。 3. 主观性: - 描述:0 到 1 之间的分数,代表推文的主观程度。 0 分表示该推文是客观的,而 1 分表示该推文非常主观。 - 类型:浮点型(范围:0 到 1)。 - 目的:表明推文中有多少内容是基于个人观点与事实信息。这对于识别更受观点驱动的推文非常有用。 4. 极性: - 描述:情绪极性得分,范围从 - 1(极度负面)到 1(极度正面)。 - 类型:浮点型(范围: - 1 到 1)。 - 目的:用于确定推文的情绪基调,无论是消极、中性还是积极。本专栏是情感分析任务的关键。 5. 目标: - 描述:一个二进制变量,表示推文对辉瑞疫苗的整体情绪。值为 0 表示负面情绪,值为 1 表示正面情绪。 - 类型:整数(0 或 1)。 - 目的:作为机器学习的目标标签
常见问题
辉瑞 (Pfizer) - AntiCovid是什么?
该数据集《Twitter Pfizer - AntiCovid》主要用于二分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
辉瑞 (Pfizer) - AntiCovid是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用辉瑞 (Pfizer) - AntiCovid?
在本页登录后即可下载。建议引用格式:地球资源数据云. 辉瑞 (Pfizer) - AntiCovid. https://www.gis5g.com/dataset/2032004067528970242