地球资源数据云——数据资源详情
NLP项目的情感分析数据集
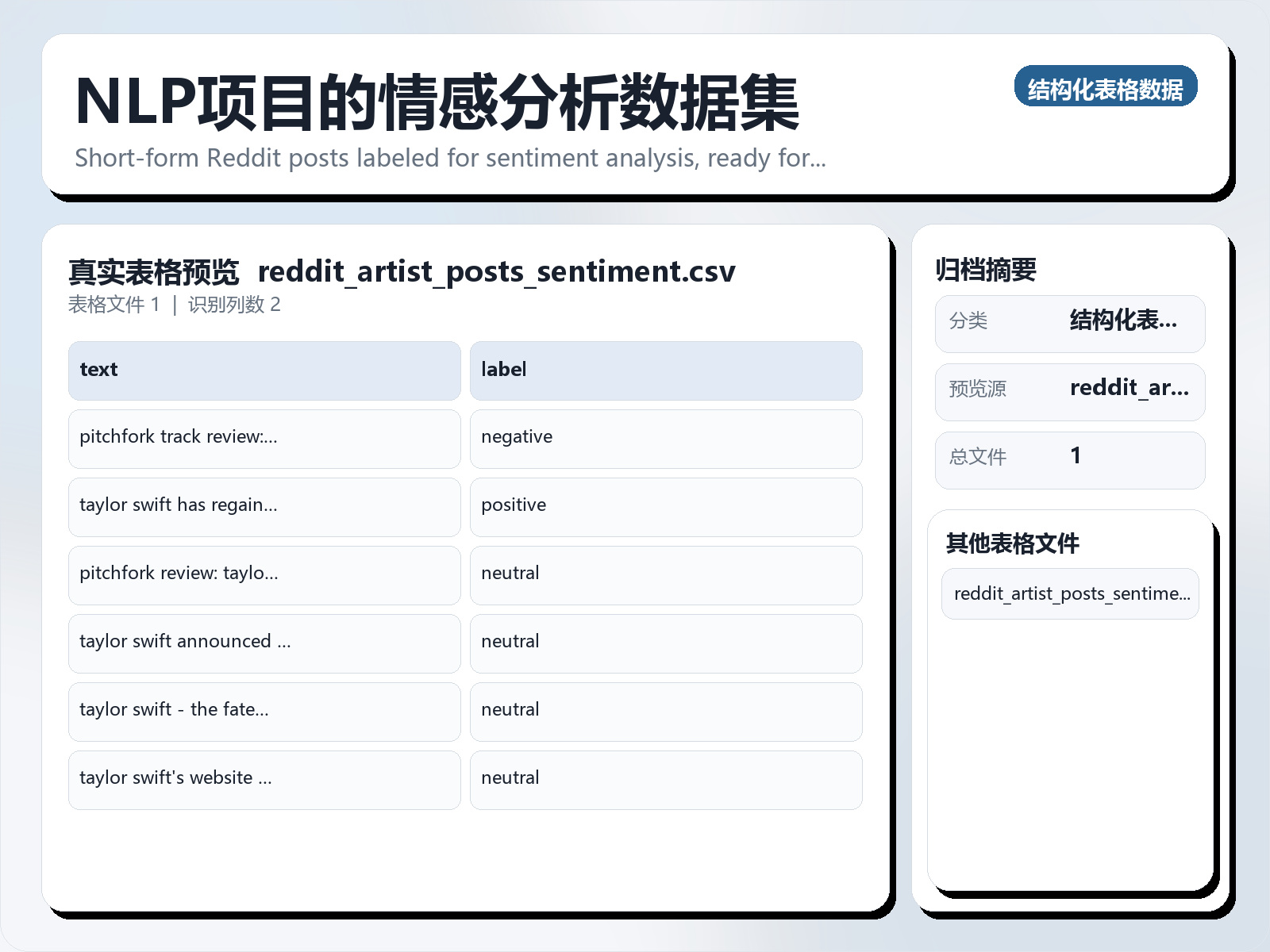
该数据集《Sentiment Analysis Dataset for NLP Projects》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Short - form Reddit posts labeled for sentiment analysis, ready for NLP projects. 任务类型:文本多分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:reddit_artist_posts_sentiment.csv。 About Dataset This dataset contains short Reddit posts (≤280 characters) about pop music and pop stars, labeled for sentiment analysis. We collected ~124k posts using keywords like Taylor Swift, Olivia Rodrigo, Grammy, Billboard, and subreddits like popheads, Music, and Billboard. After cleaning and filtering, we kept only short - form, English posts and combined each post’s title and body into a single text column. The final data set is about 32,000+ rows Sentiment labels (positive, neutral, negative) were generated using a BERT - based model fine - tuned for social media (CardiffNLP’s Twitter RoBERTa).
摘要概览
该数据集《Sentiment Analysis Dataset for NLP Projects》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Short - form Reddit posts labeled for sentiment analysis, ready for NLP projects.
任务类型:文本多分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:reddit_artist_posts_sentiment.csv。
About Dataset
This dataset contains short Reddit posts (≤280 characters) about pop music and pop stars, labeled for sentiment analysis.
We collected ~124k posts using keywords like Taylor Swift, Olivia Rodrigo, Grammy, Billboard, and subreddits like popheads, Music, and Billboard. After cleaning and filtering, we kept only short - form, English posts and combined each post’s title and body into a single text column.
The final data set is about 32,000+ rows
Sentiment labels (positive, neutral, negative) were generated using a BERT - based model fine - tuned for social media (CardiffNLP’s Twitter RoBERTa).
常见问题
NLP项目的情感分析数据集是什么?
该数据集《Sentiment Analysis Dataset for NLP Projects》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
NLP项目的情感分析数据集是什么数据格式?坐标系是什么?
数据格式为 CSV。
NLP项目的情感分析数据集是如何生产或处理的?
We collected ~124k posts using keywords like Taylor Swift, Olivia Rodrigo, Grammy, Billboard, and subreddits like popheads, Music, and Billboard.
如何获取并引用NLP项目的情感分析数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. NLP项目的情感分析数据集. https://www.gis5g.com/dataset/2032003784681885697