地球资源数据云——数据资源详情
宪法数据集
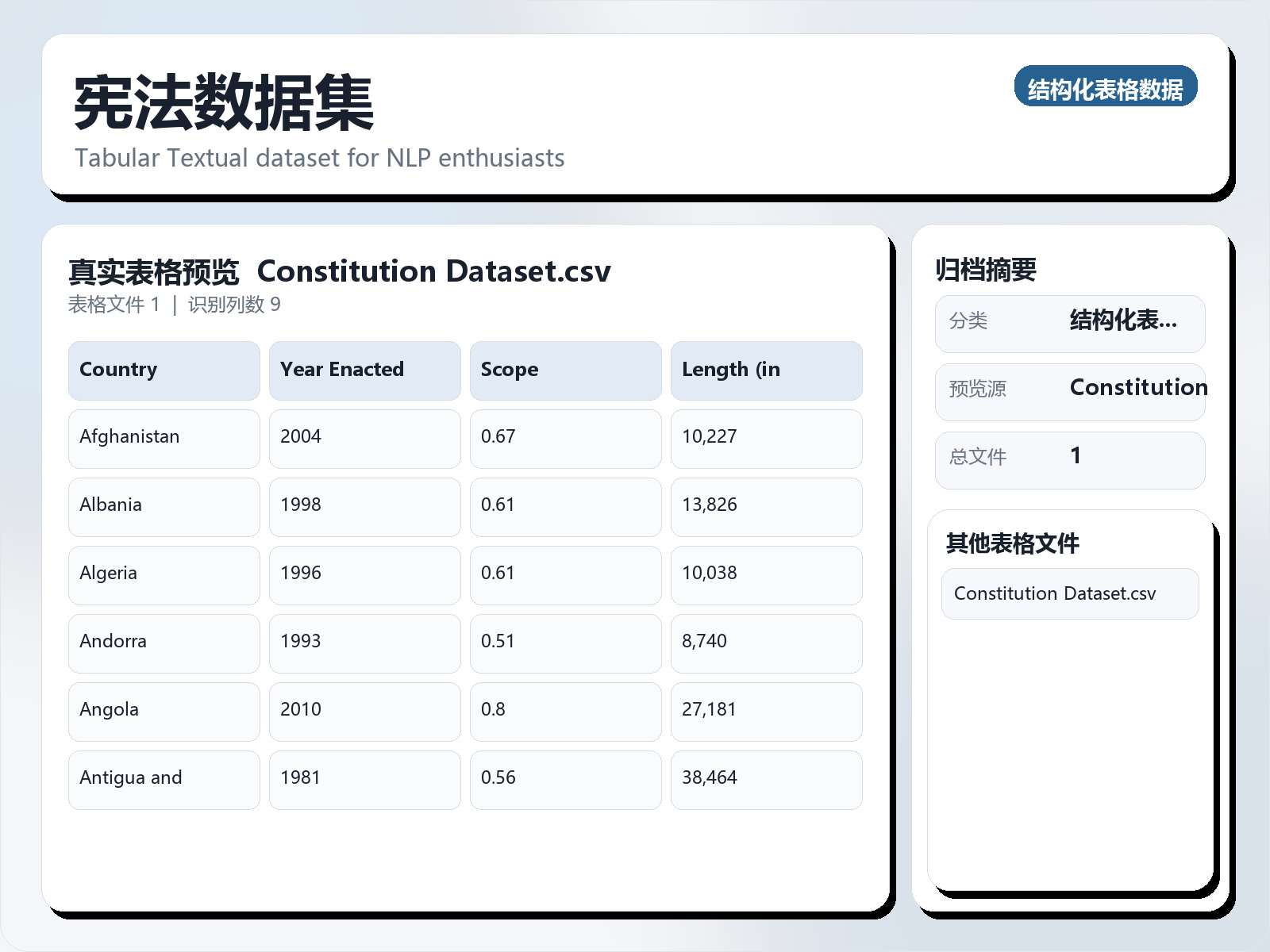
该数据集《Constitution Dataset》主要用于二分类任务,数据形态以文本为主。 题目说明:Tabular Textual dataset for NLP enthusiasts 任务类型:文本二分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:Constitution Dataset.csv。 Data is sourced from Comparative Constitutions Project (CCP). This dataset is useful for exploratory data analysis and NLP practices. Content Scope — This is drawn from Elkins, Ginsburg and Melton, The Endurance of National Constitutions (Cambridge University Press, 2009). It measures the percentage of 701 major topics from the CCP survey that are included in any given constitution. Length (in Words) — This is simply a report of the total number of words in the Constitution as measured by Microsoft Word. Executive Power— This is an additive index drawn from a working paper, Constitutional Constraints on Executive Lawmaking.
摘要概览
该数据集《Constitution Dataset》主要用于二分类任务,数据形态以文本为主。 题目说明:Tabular Textual dataset for NLP enthusiasts
任务类型:文本二分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:Constitution Dataset.csv。
Data is sourced from Comparative Constitutions Project (CCP). This dataset is useful for exploratory data analysis and NLP practices.
Content
Scope — This is drawn from Elkins, Ginsburg and Melton, The Endurance of National Constitutions (Cambridge University Press, 2009). It measures the percentage of 701 major topics from the CCP survey that are included in any given constitution.
Length (in Words) — This is simply a report of the total number of words in the Constitution as measured by Microsoft Word.
Executive Power— This is an additive index drawn from a working paper, Constitutional Constraints on Executive Lawmaking.
常见问题
宪法数据集是什么?
该数据集《Constitution Dataset》主要用于二分类任务,数据形态以文本为主。
宪法数据集是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用宪法数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. 宪法数据集. https://www.gis5g.com/dataset/2032003504766619649