地球资源数据云——数据资源详情
深度自然语言处理
该数据集《Deep - NLP》主要用于多分类任务,数据形态以图像为主,应用场景偏向安全检测。 题目说明:natural language processing 任务类型:图像多分类。 建议流程:先检查类别分布与脏样本,再用迁移学习(如 ResNet/EfficientNet)建立基线。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:Sheet_1.csv, Sheet_2.csv。 What's In The Deep - NLP Dataset? Sheet_1.csv contains 80 user responses, in the response_text column, to a therapy chatbot. Bot said: 'Describe a time when you have acted as a resource for someone else'. User responded. If a response is 'not flagged', the user can continue talking to the bot. If it is 'flagged', the user is referred to help. Sheet_2.csv contains 125 resumes, in the resume_text column. Resumes were queried from Indeed.com with keyword 'data scientist', location 'Vermont'. If a resume is 'not flagged', the applicant can submit a modified resume version at a later date. If it is 'flagged', the applicant is invited to interview. What Do I Do With This? There are two sets of data here - resumes and responses. Split the data into a train set and a test set to test the accuracy of your classifier. Bonus points for using the same classifier for both problems.
摘要概览
该数据集《Deep - NLP》主要用于多分类任务,数据形态以图像为主,应用场景偏向安全检测。 题目说明:natural language processing
任务类型:图像多分类。
建议流程:先检查类别分布与脏样本,再用迁移学习(如 ResNet/EfficientNet)建立基线。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:Sheet_1.csv, Sheet_2.csv。
What's In The Deep - NLP Dataset?
Sheet_1.csv contains 80 user responses, in the response_text column, to a therapy chatbot. Bot said: 'Describe a time when you have acted as a resource for someone else'. User responded. If a response is 'not flagged', the user can continue talking to the bot. If it is 'flagged', the user is referred to help.
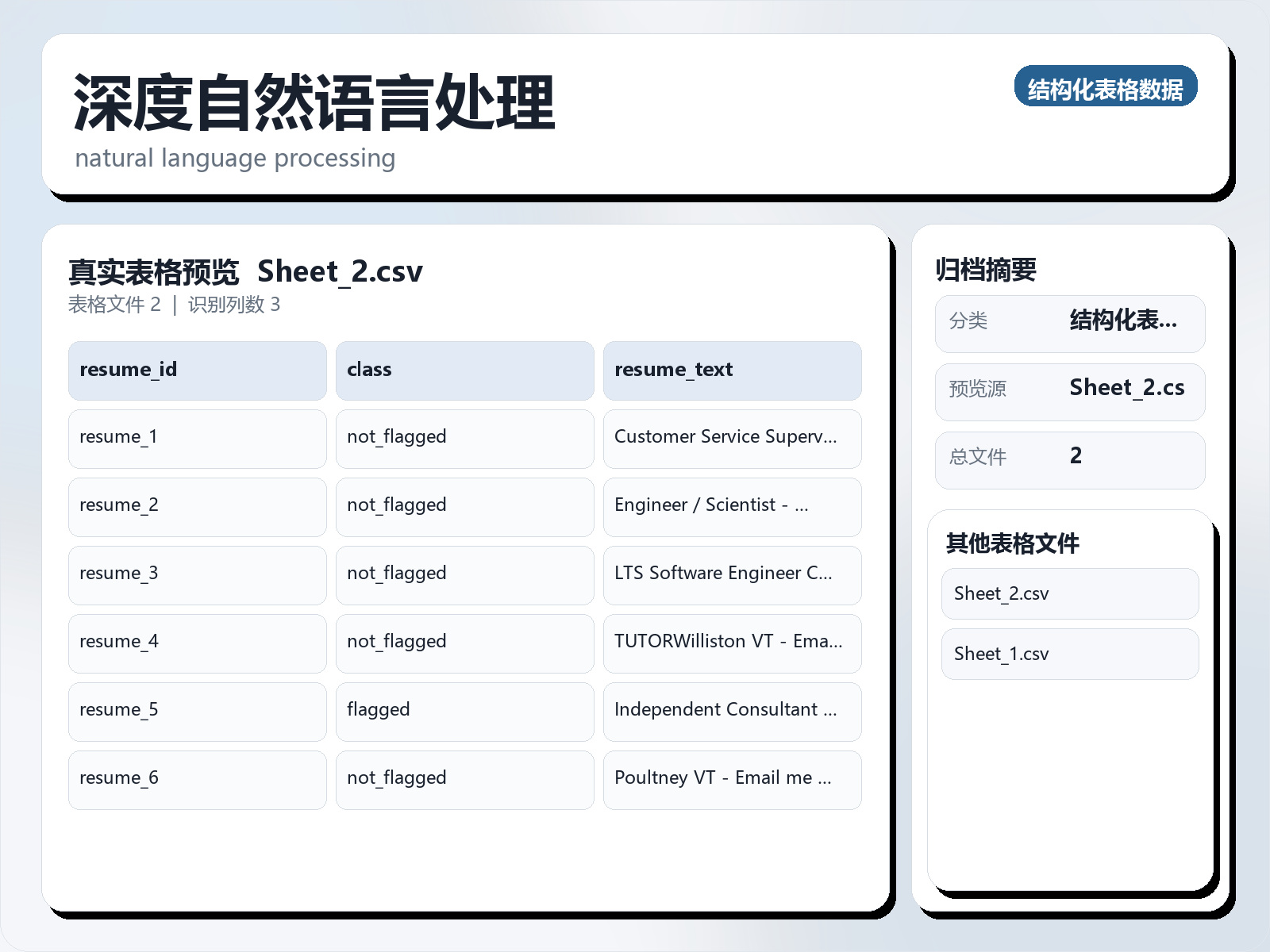
Sheet_2.csv contains 125 resumes, in the resume_text column. Resumes were queried from Indeed.com with keyword 'data scientist', location 'Vermont'. If a resume is 'not flagged', the applicant can submit a modified resume version at a later date. If it is 'flagged', the applicant is invited to interview.
What Do I Do With This?
There are two sets of data here - resumes and responses. Split the data into a train set and a test set to test the accuracy of your classifier. Bonus points for using the same classifier for both problems.
常见问题
深度自然语言处理是什么?
该数据集《Deep - NLP》主要用于多分类任务,数据形态以图像为主,应用场景偏向安全检测。
深度自然语言处理是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用深度自然语言处理?
在本页登录后即可下载。建议引用格式:地球资源数据云. 深度自然语言处理. https://www.gis5g.com/dataset/2032002577288564738