地球资源数据云——数据资源详情
Students_Academic_Performance_Dataset 学生_学术_表现_数据集
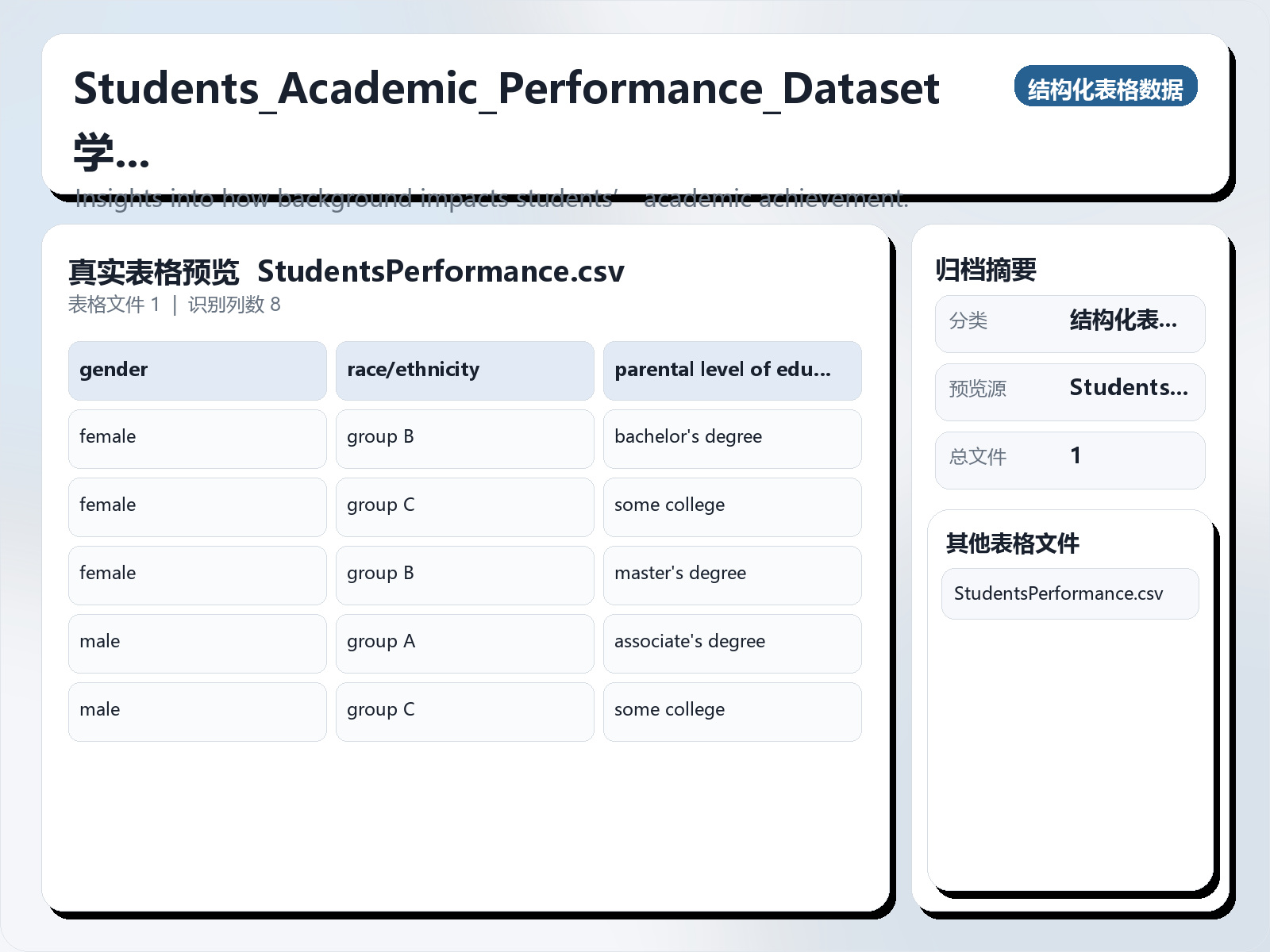
该数据集《Students_Academic_Performance_Dataset》主要用于监督学习任务,数据形态以表格为主,应用场景偏向安全检测。 题目说明:Insights into how background impacts students’ academic achievement. 任务类型:表格监督学习。 建议流程:先做缺失值/异常值处理与特征编码,再比较逻辑回归、随机森林、XGBoost。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:StudentsPerformance.csv。 Dataset Description The Students Performance dataset contains detailed information on 1,000 students. It focuses on their demographic background, parental education level, and performance in three standardized test subjects: math, reading, and writing. This dataset is widely used for exploring the relationships between socioeconomic factors and academic achievement, as well as for building prediction models to understand what influences student performance. There are 8 columns in total, covering both categorical and numerical variables. The categorical features include gender, race/ethnicity, parental level of education, lunch type, and whether the student completed a test preparation course. The numerical features include scores in math, reading, and writing — each ranging from 0 to 100. The dataset has no missing values, making it clean and ready for analysis. It consists of 1,000 rows and 8 columns in total.
摘要概览
该数据集《Students_Academic_Performance_Dataset》主要用于监督学习任务,数据形态以表格为主,应用场景偏向安全检测。 题目说明:Insights into how background impacts students’ academic achievement.
任务类型:表格监督学习。
建议流程:先做缺失值/异常值处理与特征编码,再比较逻辑回归、随机森林、XGBoost。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:StudentsPerformance.csv。
Dataset Description
The Students Performance dataset contains detailed information on 1,000 students. It focuses on their demographic background, parental education level, and performance in three standardized test subjects: math, reading, and writing.
This dataset is widely used for exploring the relationships between socioeconomic factors and academic achievement, as well as for building prediction models to understand what influences student performance.
There are 8 columns in total, covering both categorical and numerical variables. The categorical features include gender, race/ethnicity, parental level of education, lunch type, and whether the student completed a test preparation course. The numerical features include scores in math, reading, and writing — each ranging from 0 to 100.
The dataset has no missing values, making it clean and ready for analysis. It consists of 1,000 rows and 8 columns in total.
常见问题
Students_Academic_Performance_Dataset 学生_学术_表现_数据集是什么?
该数据集《Students_Academic_Performance_Dataset》主要用于监督学习任务,数据形态以表格为主,应用场景偏向安全检测。
Students_Academic_Performance_Dataset 学生_学术_表现_数据集是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用Students_Academic_Performance_Dataset 学生_学术_表现_数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. Students_Academic_Performance_Dataset 学生_学术_表现_数据集. https://www.gis5g.com/dataset/2031997359192707074