地球资源数据云——数据资源详情
数字素养教育数据集
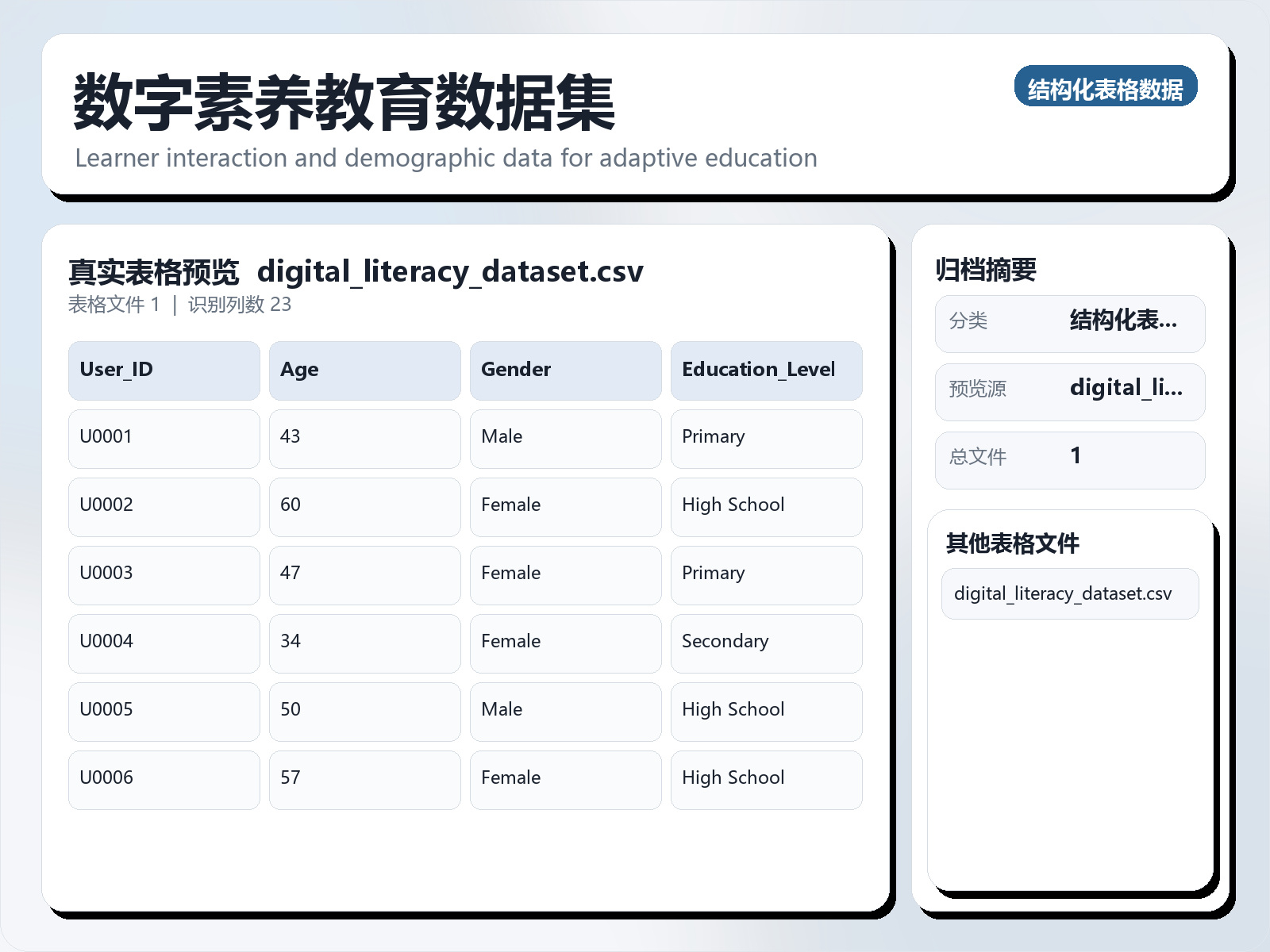
该数据集《Digital Literacy Education Dataset》主要用于监督学习任务,数据形态以表格为主。 题目说明:Learner interaction and demographic data for adaptive education systems 任务类型:表格监督学习。 建议流程:先做缺失值/异常值处理与特征编码,再比较逻辑回归、随机森林、XGBoost。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:digital_literacy_dataset.csv。 This dataset is designed to support research and development in improving digital literacy education in rural areas, with a focus on rural revitalization. It includes comprehensive learner interaction data, demographic attributes, and post - training outcomes, making it suitable for building adaptive and personalized learning systems. Key features of this dataset include: Demographics: Information on age, gender, education level, employment status, household income, and location type. Pre - Training Scores: Baseline scores for basic computer knowledge, internet usage, and mobile literacy. Post - Training Progress: Scores achieved after training to track the impact of education modules. Engagement Metrics: Data on session counts, modules completed, average time spent per module, and quiz performance. Behavioral Insights: Engagement levels, adaptability scores, and learner feedback ratings. Outcome Measures: Overall digital literacy scores, skill application data, and employment impact information. This dataset is ideal for: Training and testing machine learning models for adaptive learning systems. Analyzing the effectiveness of digital literacy programs. Gaining insights into learner behavior and progress.
摘要概览
该数据集《Digital Literacy Education Dataset》主要用于监督学习任务,数据形态以表格为主。 题目说明:Learner interaction and demographic data for adaptive education systems
任务类型:表格监督学习。
建议流程:先做缺失值/异常值处理与特征编码,再比较逻辑回归、随机森林、XGBoost。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:digital_literacy_dataset.csv。
This dataset is designed to support research and development in improving digital literacy education in rural areas, with a focus on rural revitalization. It includes comprehensive learner interaction data, demographic attributes, and post - training outcomes, making it suitable for building adaptive and personalized learning systems.
Key features of this dataset include:
Demographics: Information on age, gender, education level, employment status, household income, and location type. Pre - Training Scores: Baseline scores for basic computer knowledge, internet usage, and mobile literacy. Post - Training Progress: Scores achieved after training to track the impact of education modules.
Engagement Metrics: Data on session counts, modules completed, average time spent per module, and quiz performance. Behavioral Insights: Engagement levels, adaptability scores, and learner feedback ratings. Outcome Measures: Overall digital literacy scores, skill application data, and employment impact information. This dataset is ideal for:
Training and testing machine learning models for adaptive learning systems. Analyzing the effectiveness of digital literacy programs. Gaining insights into learner behavior and progress.
常见问题
数字素养教育数据集是什么?
该数据集《Digital Literacy Education Dataset》主要用于监督学习任务,数据形态以表格为主。
数字素养教育数据集是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用数字素养教育数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. 数字素养教育数据集. https://www.gis5g.com/dataset/2031927170191233025