地球资源数据云——数据资源详情
带有消费者评级的餐厅数据
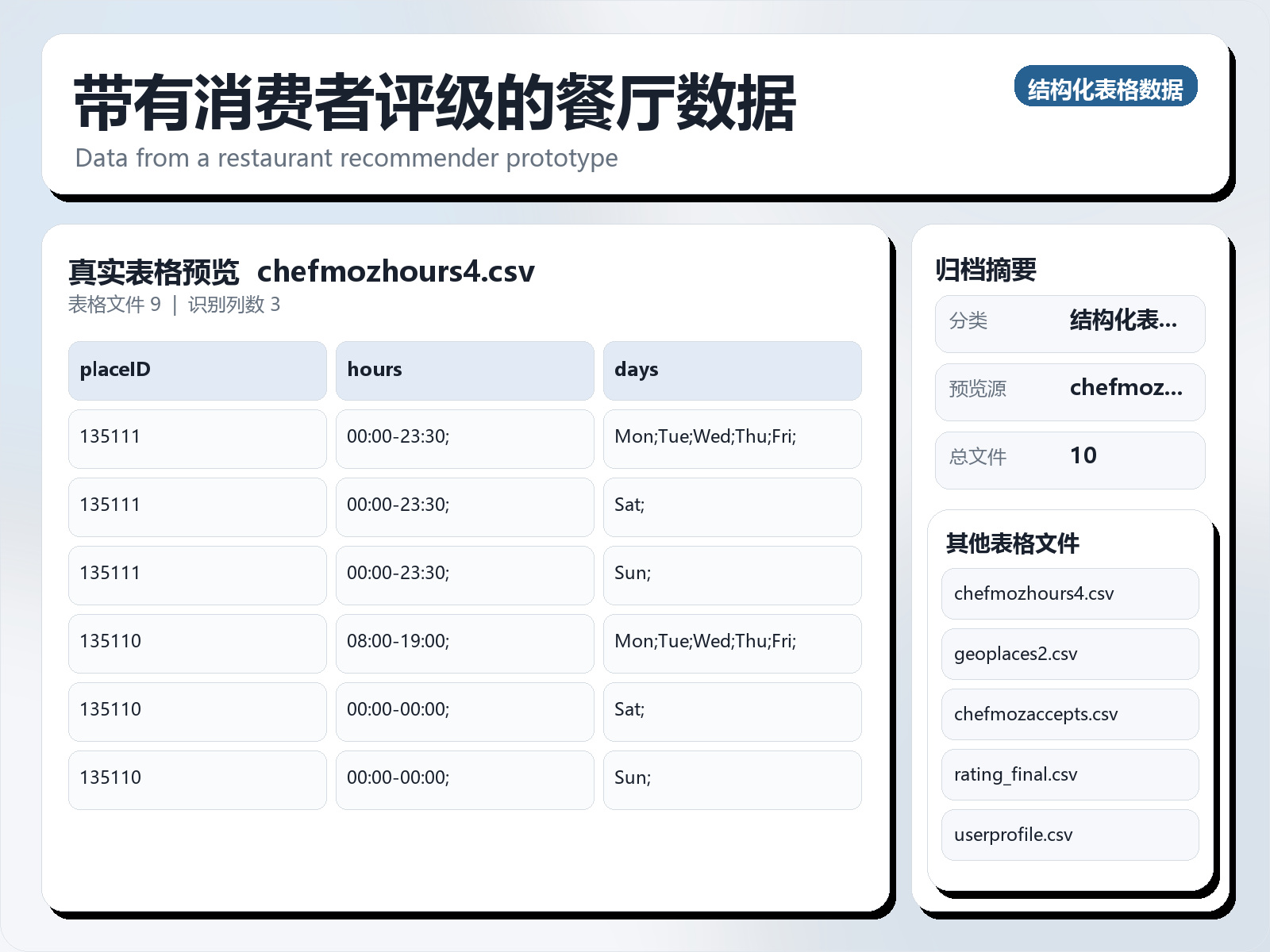
该数据集《Restaurant Data with Consumer Ratings》主要用于监督学习任务,数据形态以文本为主。 题目说明:Data from a restaurant recommender prototype 任务类型:文本监督学习。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:chefmozaccepts.csv, chefmozcuisine.csv, chefmozhours4.csv 等 9 个文件。 Context This dataset was used for a study where the task was to generate a top - n list of restaurants according to the consumer preferences and finding the significant features. Two approaches were tested: a collaborative filter technique and a contextual approach: (i) The collaborative filter technique used only one file i.e., rating_final.csv that comprises the user, item and rating attributes. (ii) The contextual approach generated the recommendations using the remaining eight data files. Content There are 9 data files and a README, and are grouped like this:
摘要概览
该数据集《Restaurant Data with Consumer Ratings》主要用于监督学习任务,数据形态以文本为主。 题目说明:Data from a restaurant recommender prototype
任务类型:文本监督学习。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:chefmozaccepts.csv, chefmozcuisine.csv, chefmozhours4.csv 等 9 个文件。
Context
This dataset was used for a study where the task was to generate a top - n list of restaurants according to the consumer preferences and finding the significant features.
Two approaches were tested: a collaborative filter technique and a contextual approach: (i) The collaborative filter technique used only one file i.e., rating_final.csv that comprises the user, item and rating attributes. (ii) The contextual approach generated the recommendations using the remaining eight data files.
Content
There are 9 data files and a README, and are grouped like this:
常见问题
带有消费者评级的餐厅数据是什么?
该数据集《Restaurant Data with Consumer Ratings》主要用于监督学习任务,数据形态以文本为主。
带有消费者评级的餐厅数据是什么数据格式?坐标系是什么?
数据格式为 CSV。
带有消费者评级的餐厅数据是如何生产或处理的?
(ii) The contextual approach generated the recommendations using the remaining eight data files.
如何获取并引用带有消费者评级的餐厅数据?
在本页登录后即可下载。建议引用格式:地球资源数据云. 带有消费者评级的餐厅数据. https://www.gis5g.com/dataset/2031261957129408513