地球资源数据云——数据资源详情
IRIS 数据集 - 分类
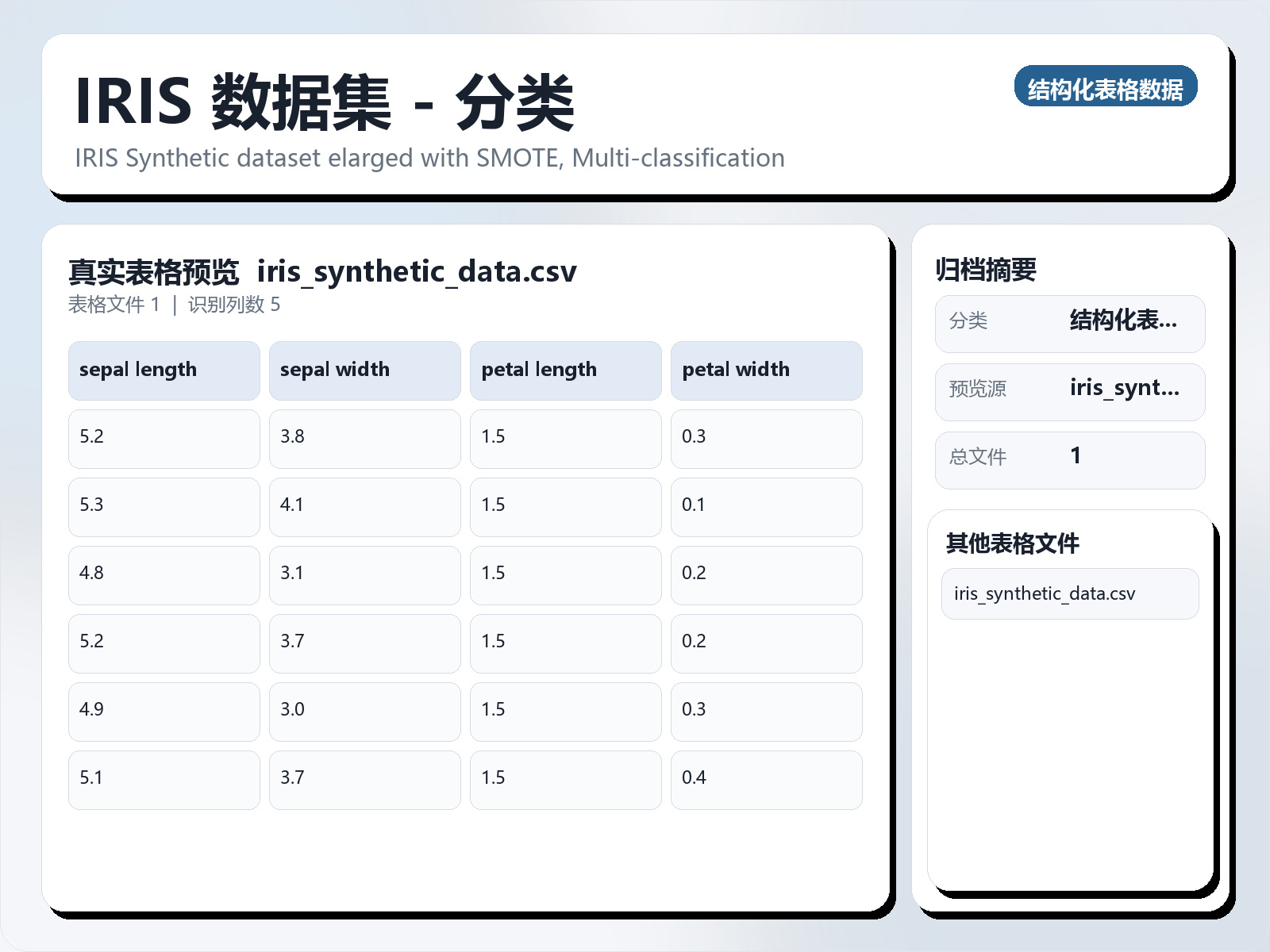
该数据集《IRIS dataset - Classification》主要用于多分类任务,数据形态以表格为主。 题目说明:IRIS Synthetic dataset elarged with SMOTE, Multi - classification 任务类型:表格多分类。 建议流程:先做缺失值/异常值处理与特征编码,再比较逻辑回归、随机森林、XGBoost。 注意事项:疑似存在类别不均衡,建议使用分层抽样、类别权重与 F1/Recall 指标。 可用文件:iris_synthetic_data.csv。 1. Data Source & Process The original dataset is the Iris Dataset from the UCI Machine Learning Repository. To address potential class imbalance, SMOTE - ENN (Synthetic Minority Oversampling Technique + Edited Nearest Neighbors) was applied, generating a balanced synthetic dataset. Each class now contains exactly 1,000 instances, resulting in a total of 3,000 records. 2. Metadata The dataset contains 3,000 records with 5 variables, described as follows: | Column | Description | Type |
摘要概览
该数据集《IRIS dataset - Classification》主要用于多分类任务,数据形态以表格为主。 题目说明:IRIS Synthetic dataset elarged with SMOTE, Multi - classification
任务类型:表格多分类。
建议流程:先做缺失值/异常值处理与特征编码,再比较逻辑回归、随机森林、XGBoost。
注意事项:疑似存在类别不均衡,建议使用分层抽样、类别权重与 F1/Recall 指标。
可用文件:iris_synthetic_data.csv。
1. Data Source & Process
The original dataset is the Iris Dataset from the UCI Machine Learning Repository. To address potential class imbalance, SMOTE - ENN (Synthetic Minority Oversampling Technique + Edited Nearest Neighbors) was applied, generating a balanced synthetic dataset. Each class now contains exactly 1,000 instances, resulting in a total of 3,000 records.
2. Metadata
The dataset contains 3,000 records with 5 variables, described as follows:
| Column | Description | Type |
常见问题
IRIS 数据集 - 分类是什么?
该数据集《IRIS dataset - Classification》主要用于多分类任务,数据形态以表格为主。
IRIS 数据集 - 分类是什么数据格式?坐标系是什么?
数据格式为 CSV。
IRIS 数据集 - 分类是如何生产或处理的?
题目说明:IRIS Synthetic dataset elarged with SMOTE, Multi - classification 任务类型:表格多分类。
如何获取并引用IRIS 数据集 - 分类?
在本页登录后即可下载。建议引用格式:地球资源数据云. IRIS 数据集 - 分类. https://www.gis5g.com/dataset/2031258753876529154