地球资源数据云——数据资源详情
情绪分类自然语言处理
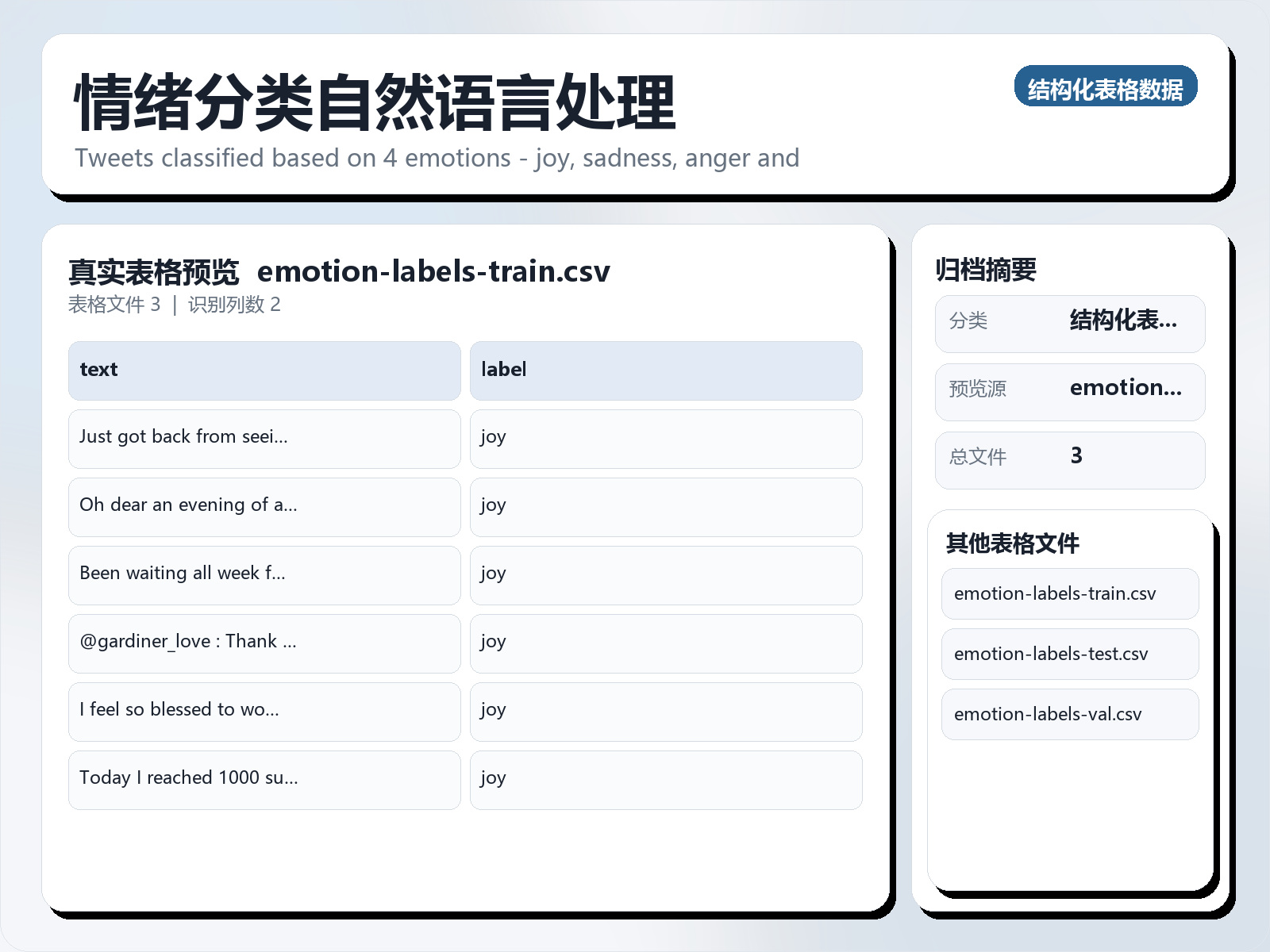
该数据集《Emotion Classification NLP》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Tweets classified based on 4 emotions - joy, sadness, anger and fear. 任务类型:文本多分类。 建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。 评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。 可用文件:emotion - labels - test.csv, emotion - labels - train.csv, emotion - labels - val.csv。 Context Identifying emotions has become an integral part of many NLP and data science projects. With the help of this dataset, one can train and build various robust models and perform emotional analysis. Content Manual annotation of the dataset to obtain real - valued scores was done through Best - Worst Scaling (BWS), an annotation scheme shown to obtain very reliable scores (Kiritchenko and Mohammad, 2016). The data is then split into a training set and a test set. Acknowledgements
摘要概览
该数据集《Emotion Classification NLP》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。 题目说明:Tweets classified based on 4 emotions - joy, sadness, anger and fear.
任务类型:文本多分类。
建议流程:先做文本清洗与分词,再比较 TF - IDF+线性模型 与 预训练语言模型。
评估建议:使用分层切分或交叉验证,优先关注 F1、Recall、AUC 等分类指标。
可用文件:emotion - labels - test.csv, emotion - labels - train.csv, emotion - labels - val.csv。
Context
Identifying emotions has become an integral part of many NLP and data science projects. With the help of this dataset, one can train and build various robust models and perform emotional analysis.
Content
Manual annotation of the dataset to obtain real - valued scores was done through Best - Worst Scaling (BWS), an annotation scheme shown to obtain very reliable scores (Kiritchenko and Mohammad, 2016). The data is then split into a training set and a test set.
Acknowledgements
常见问题
情绪分类自然语言处理是什么?
该数据集《Emotion Classification NLP》主要用于多分类任务,数据形态以文本为主,应用场景偏向文本内容分析。
情绪分类自然语言处理是什么数据格式?坐标系是什么?
数据格式为 CSV。
如何获取并引用情绪分类自然语言处理?
在本页登录后即可下载。建议引用格式:地球资源数据云. 情绪分类自然语言处理. https://www.gis5g.com/dataset/2031256973637750785