地球资源数据云——数据资源详情
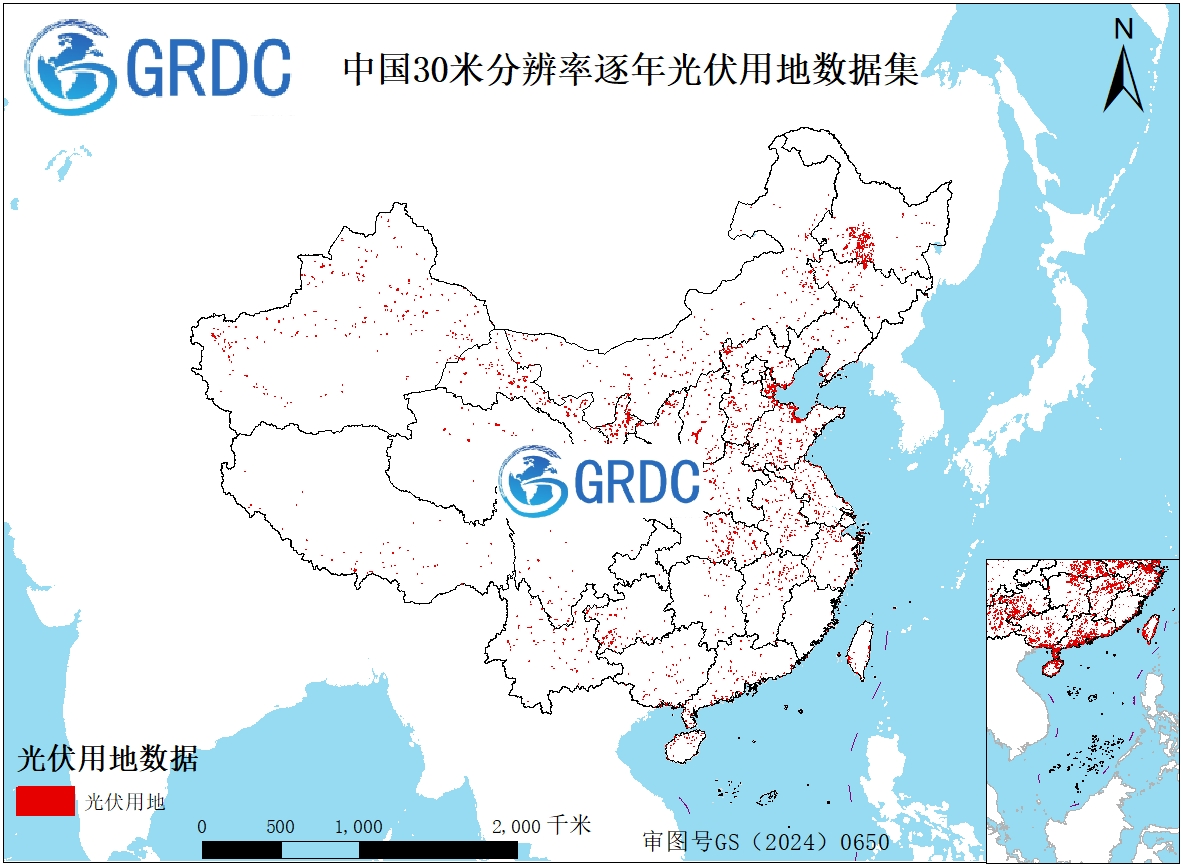
基于随机森林2017-2024年中国30米分辨率光伏用地数据集
摘要 : 本数据集基于 Google 地球引擎的 “ SATELLITE_EMBEDDING/V1/ANNUAL ”数据集所提供的深度特征,利用高性能计算的随机森林分类模型,生成了 2017 年至 2024 年间覆盖中国范围的 30 米空间分辨率光伏用地专题产品。该数据集的核心方法在于利用预训练的卫星嵌入向量作为输入特征,有效捕捉地物光谱与纹理的复杂模式,从而实现对地面光伏设施高精度的自动识别与提取。数据集在时间上形成了连续八年的动态监测序列,在空间上以标准地理网格完整呈现,具备良好的时空一致性与可比性。通过多轮样本抽样与人工交互验证,数据集的质量得到了有效控制。本数据集为系统评估中国光伏发电产业的发展历程、分析其土地利用格局演变、以及深入研究可再生能源部署的生态环境影响提供了不可或缺的基础数据和科学依据。 关键词 : 光伏;多元遥感数据融合;地理空间嵌入模型; 随机森林 ; 30 米分辨率 引 言 在全球应对气候变化、推动能源结构转型的宏大背景下,中国提出了 “碳达峰”与“碳中和”(简称“双碳”)的重大战略目标。实现这一目标的核心路径在于构建以可再生能源为主体的新型电力系统。其中,光伏发电凭借其资源分布广泛、技术可及性高及成本持续下降等优势,已成为全球能源绿色低碳转型的主力军。准确、及时地掌握光伏设施的时空分布与动态变化,对于评估光伏产能、优化能源布局、衡量“双碳”进程乃至评估其对生态环境的影响具有至关重要的意义。 传统的能源统计方法难以提供高时空分辨率的地理空间信息,而遥感技术为大范围、高效率地监测地表光伏设施提供了有效手段。近年来,基于遥感影像的光伏用地识别研究取得了显著进展,尤其是像随机森林这类机器学习算法,因其在处理复杂非线性地物分类问题上的优异性能而被广泛应用。然而,构建覆盖广大区域、具备时间序列一致性且精度可靠的光伏数据集仍是一项挑战。 本研究基于 Google Earth Engine 平台的 SATELLITE_EMBEDDING/V1/ANNUAL 数据集,利用其提供的深度影像嵌入特征,训练了随机森林分类模型,旨在生成一套覆盖中国、空间分辨率为 30 米、时间跨度为 2017 年至 2024 年的年度光伏用地数据集。本工作是对已有光伏测绘研究在时空范围和自动化程度上的进一步拓展与深化。 本数据集不仅能够为 “双碳”目标下的能源政策评估提供关键的数据支撑,其长时间序列的特性也使其在土地利用 / 覆被变化研究、区域生态环境效应评估、以及作为其他地球系统模型(如气候模型、水文模型)的输入数据方面,展现出巨大的潜在重用价值。 1 数据采集和处理方法 1.1 数据采集方法 数据采集主要依靠 GEE ( Google Earth Engine )平台,本数据主要使用了三种数据集,分别是由 Google DeepMind 与 Google Earth Engine 联合发布的 10 米分辨率的多源遥感融合数据集 'GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL' , 10 米分辨率的哨兵 2 数据集 'COPERNICUS/S2_SR_HARMONIZED' 和由欧空局发布的 10 米分辨率土地利用数据集 'ESA/WorldCover/v100' ,土地利用数据共分为 11 个类别,分别为 树木覆盖区 、 灌木覆盖区 、 草地 、 耕地 、 建筑区 、 裸地 / 稀疏植被区 、 雪和冰 、 水体 、 红树林 、 苔原 、 永久性水体 。
摘要概览
摘要 : 本数据集基于 Google 地球引擎的 “ SATELLITE_EMBEDDING/V1/ANNUAL ”数据集所提供的深度特征,利用高性能计算的随机森林分类模型,生成了 2017 年至 2024 年间覆盖中国范围的 30 米空间分辨率光伏用地专题产品。该数据集的核心方法在于利用预训练的卫星嵌入向量作为输入特征,有效捕捉地物光谱与纹理的复杂模式,从而实现对地面光伏设施高精度的自动识别与提取。数据集在时间上形成了连续八年的动态监测序列,在空间上以标准地理网格完整呈现,具备良好的时空一致性与可比性。通过多轮样本抽样与人工交互验证,数据集的质量得到了有效控制。本数据集为系统评估中国光伏发电产业的发展历程、分析其土地利用格局演变、以及深入研究可再生能源部署的生态环境影响提供了不可或缺的基础数据和科学依据。
关键词 : 光伏;多元遥感数据融合;地理空间嵌入模型; 随机森林 ; 30 米分辨率
引 言
在全球应对气候变化、推动能源结构转型的宏大背景下,中国提出了 “碳达峰”与“碳中和”(简称“双碳”)的重大战略目标。实现这一目标的核心路径在于构建以可再生能源为主体的新型电力系统。其中,光伏发电凭借其资源分布广泛、技术可及性高及成本持续下降等优势,已成为全球能源绿色低碳转型的主力军。准确、及时地掌握光伏设施的时空分布与动态变化,对于评估光伏产能、优化能源布局、衡量“双碳”进程乃至评估其对生态环境的影响具有至关重要的意义。
传统的能源统计方法难以提供高时空分辨率的地理空间信息,而遥感技术为大范围、高效率地监测地表光伏设施提供了有效手段。近年来,基于遥感影像的光伏用地识别研究取得了显著进展,尤其是像随机森林这类机器学习算法,因其在处理复杂非线性地物分类问题上的优异性能而被广泛应用。然而,构建覆盖广大区域、具备时间序列一致性且精度可靠的光伏数据集仍是一项挑战。
本研究基于 Google Earth Engine 平台的 SATELLITE_EMBEDDING/V1/ANNUAL 数据集,利用其提供的深度影像嵌入特征,训练了随机森林分类模型,旨在生成一套覆盖中国、空间分辨率为 30 米、时间跨度为 2017 年至 2024 年的年度光伏用地数据集。本工作是对已有光伏测绘研究在时空范围和自动化程度上的进一步拓展与深化。
本数据集不仅能够为 “双碳”目标下的能源政策评估提供关键的数据支撑,其长时间序列的特性也使其在土地利用 / 覆被变化研究、区域生态环境效应评估、以及作为其他地球系统模型(如气候模型、水文模型)的输入数据方面,展现出巨大的潜在重用价值。
1 数据采集和处理方法
1.1 数据采集方法
数据采集主要依靠 GEE ( Google Earth Engine )平台,本数据主要使用了三种数据集,分别是由 Google DeepMind 与 Google Earth Engine 联合发布的 10 米分辨率的多源遥感融合数据集 'GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL' , 10 米分辨率的哨兵 2 数据集 'COPERNICUS/S2_SR_HARMONIZED' 和由欧空局发布的 10 米分辨率土地利用数据集 'ESA/WorldCover/v100' ,土地利用数据共分为 11 个类别,分别为 树木覆盖区 、 灌木覆盖区 、 草地 、 耕地 、 建筑区 、 裸地 / 稀疏植被区 、 雪和冰 、 水体 、 红树林 、 苔原 、 永久性水体 。
常见问题
基于随机森林2017-2024年中国30米分辨率光伏用地数据集是什么?
本数据集基于 Google 地球引擎的 “ SATELLITE_EMBEDDING/V1/ANNUAL ”数据集所提供的深度特征,利用高性能计算的随机森林分类模型,生成了 2017年至 2024年间覆盖中国范围的 30米空间分辨率光伏用地专题产品。
基于随机森林2017-2024年中国30米分辨率光伏用地数据集的数据来源是什么?
数据来源于Google 地球引擎的 “ SATELLITE_EMBEDDING/V1/ANNUAL ”,由地球资源数据云整理发布。
基于随机森林2017-2024年中国30米分辨率光伏用地数据集的时间频率是什么?
该数据集时间尺度包含年尺度或逐年变化。
基于随机森林2017-2024年中国30米分辨率光伏用地数据集的空间分辨率是多少?
该数据集空间分辨率为 30米。
基于随机森林2017-2024年中国30米分辨率光伏用地数据集覆盖什么区域?
该数据集覆盖范围为全球。
基于随机森林2017-2024年中国30米分辨率光伏用地数据集是如何生产或处理的?
1 数据采集和处理方法 1.1 数据采集方法 数据采集主要依靠 GEE (Google Earth Engine)平台,本数据主要使用了三种数据集,分别是由 Google DeepMind 与 Google Earth Engine 联合发布的 10米分辨率的多源遥感融合数据集 'GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL',…
基于随机森林2017-2024年中国30米分辨率光伏用地数据集可以用于什么?
摘要: 本数据集基于 Google 地球引擎的 “ SATELLITE_EMBEDDING/V1/ANNUAL ”数据集所提供的深度特征,利用高性能计算的随机森林分类模型,生成了 2017年至 2024年间覆盖中国范围的 30米空间分辨率光伏用地专题产品。
如何获取并引用基于随机森林2017-2024年中国30米分辨率光伏用地数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. 基于随机森林2017-2024年中国30米分辨率光伏用地数据集. https://www.gis5g.com/dataset/1996778418124337154