地球资源数据云——数据资源详情
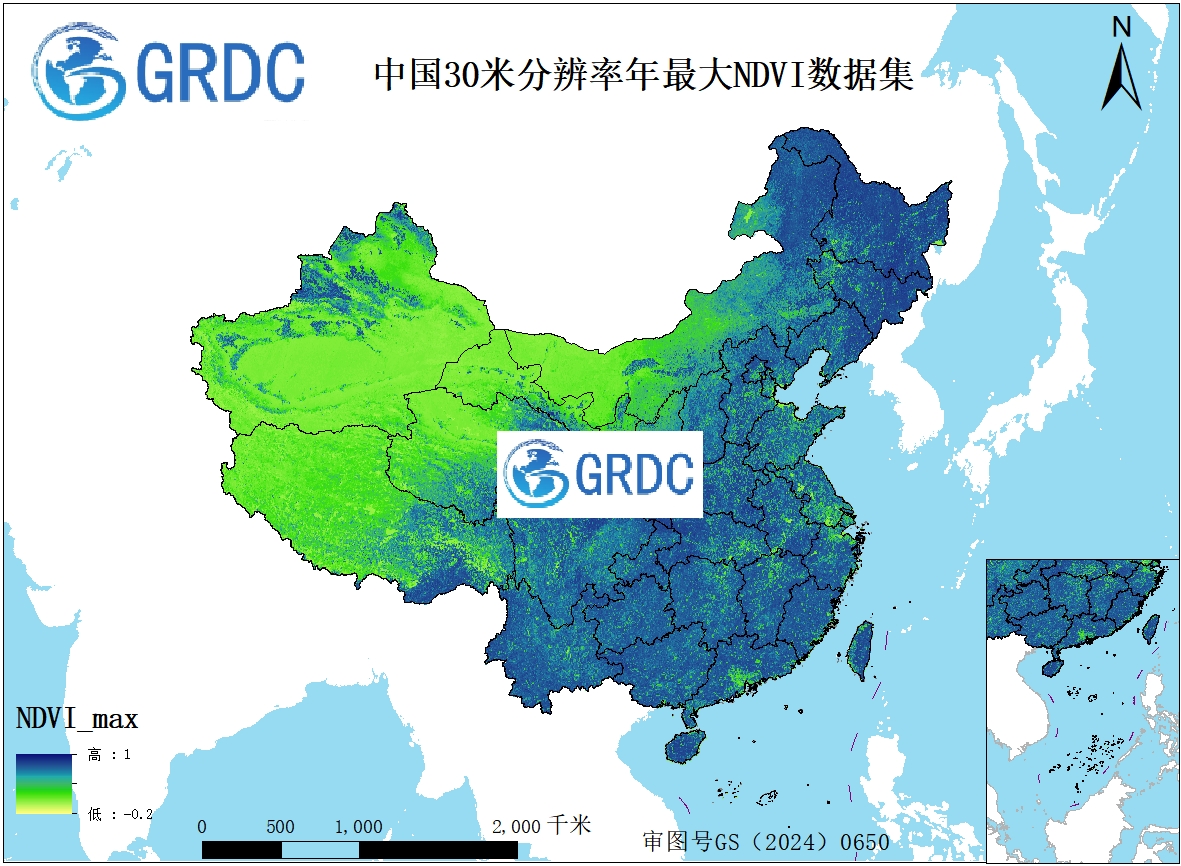
1986-2025年中国逐年30米分辨率最大值合成NDVI数据集
本数据集基于 Google Earth Engine ( GEE )平台,通过对 Landsat 系列卫星影像进行逐年最大值合成处理,生成 1986 年至 2025 年中国区域 30 米空间分辨率的年度 NDVI 数据集。数据经过辐射定标、大气校正和云掩蔽等预处理,并采用最大值合成法以削弱云和大气影响,保障数据质量的一致性。该数据集具有高时空一致性和长时间覆盖特征,适用于植被动态监测、生态环境评估及气候变化研究等领域,具有较强的科学价值和应用潜力。 关键词: GEE ;归一化植被指数; NDVI ; 30 米分辨率;最大值合成 引 言 在全球变化和可持续发展研究的宏观背景下,对地表植被动态进行长期、连续且精确的监测具有至关重要的数据科学意义。归一化植被指数( NDVI )作为量化植被覆盖度、光合作用强度及生物量的关键遥感指标,被广泛应用于生态系统健康状况评估、气候变化响应研究、农业生产估算及环境政策制定等领域。然而,传统的低分辨率 NDVI 产品(如 NOAA AVHRR 提供的 8 公里数据)难以精细刻画局地尺度的植被空间异质性,而更高分辨率的数据(如 Landsat 的 30 米分辨率)虽能弥补此缺陷,却长期受限于云污染、数据缺失以及海量数据处理的计算挑战,难以便捷地形成长时间序列的分析就绪产品。 本研究旨在构建一套 1986 年至 2025 年空间分辨率为 30 米的逐年最大 NDVI 合成数据集 。该工作的核心数据科学价值在于,它通过先进的云计算平台( Google Earth Engine )对长达四十年的 Landsat 系列卫星影像档案进行大规模并行处理,应用严格的云掩膜和大气校正算法,并采用年最大值合成法以有效消除残余噪声和季节性影响,从而生成无云、高质量、时间可比的数据。此数据集不仅延续了自上世纪 80 年代以来的高分辨率植被观测记录,更为基于长时间序列的机器学习与统计模型提供了稳定可靠的数据基础。 本工作的开展建立在众多先驱研究的基础之上,特别是对 Landsat 数据系统性处理与应用的开拓性工作,以及利用年最大值合成法生成无云植被指数产品的成熟方法论。相较于现有同类产品,本数据集以其更长的时序覆盖、一致的处理流程和高空间分辨率,展现出巨大的潜在重用价值。研究者可借此深入探究以下科学问题:城市扩张与土地利用变化的生态效应、极端气候事件(如干旱、洪涝)对植被的冲击与恢复力、以及全球变暖背景下物候特征的长期演变趋势等。该数据集的发布预期将为生态学、地理学、气候学及农学等多个交叉学科提供一项宝贵的基础数据资源,推动数据驱动下的环境科学研究迈向更深层次。 1 数据采集和处理方法 1.1 数据采集方法 数据采集主要依靠 GEE ( Google Earth Engine )平台, 1986 - 2011 年份使用 LANDSAT/LT05/C02/T1_L2 数据集。 2012 - 2013 年使用 LANDSAT/LE07/C02/T1_L2 数据集。由于 LANDSAT7 影像的 扫描行校正器( Scan Line Corrector, SLC )的永久性故障 。因此,自 2003 年 5 月 31 日之后获取的 LANDSAT 7 影像被称为 “ SLC - off ”数据 ,在 SLC - off 影像中,每一景图像都会出现 平行的、交错的数据缺失条带 。图像中间部分几乎完整,但越往边缘,条带缺失越严重,导致边缘部分约有 22% 的数据完全丢失。 所以 2012 年和 2013 年的数据采用了核函数的方法进行了修补。 2014 - 2018 年使用 LANDSAT/LC08/C02/T1_L2 数据集。 2019 - 2025 年使用 LANDSAT/LC08/C02/T1_L2 和 LANDSAT/LC09/C02/T1_L2 数据集。 1.2 数据处理
摘要概览
本数据集基于 Google Earth Engine ( GEE )平台,通过对 Landsat 系列卫星影像进行逐年最大值合成处理,生成 1986 年至 2025 年中国区域 30 米空间分辨率的年度 NDVI 数据集。数据经过辐射定标、大气校正和云掩蔽等预处理,并采用最大值合成法以削弱云和大气影响,保障数据质量的一致性。该数据集具有高时空一致性和长时间覆盖特征,适用于植被动态监测、生态环境评估及气候变化研究等领域,具有较强的科学价值和应用潜力。
关键词: GEE ;归一化植被指数; NDVI ; 30 米分辨率;最大值合成
引 言
在全球变化和可持续发展研究的宏观背景下,对地表植被动态进行长期、连续且精确的监测具有至关重要的数据科学意义。归一化植被指数( NDVI )作为量化植被覆盖度、光合作用强度及生物量的关键遥感指标,被广泛应用于生态系统健康状况评估、气候变化响应研究、农业生产估算及环境政策制定等领域。然而,传统的低分辨率 NDVI 产品(如 NOAA AVHRR 提供的 8 公里数据)难以精细刻画局地尺度的植被空间异质性,而更高分辨率的数据(如 Landsat 的 30 米分辨率)虽能弥补此缺陷,却长期受限于云污染、数据缺失以及海量数据处理的计算挑战,难以便捷地形成长时间序列的分析就绪产品。
本研究旨在构建一套 1986 年至 2025 年空间分辨率为 30 米的逐年最大 NDVI 合成数据集 。该工作的核心数据科学价值在于,它通过先进的云计算平台( Google Earth Engine )对长达四十年的 Landsat 系列卫星影像档案进行大规模并行处理,应用严格的云掩膜和大气校正算法,并采用年最大值合成法以有效消除残余噪声和季节性影响,从而生成无云、高质量、时间可比的数据。此数据集不仅延续了自上世纪 80 年代以来的高分辨率植被观测记录,更为基于长时间序列的机器学习与统计模型提供了稳定可靠的数据基础。
本工作的开展建立在众多先驱研究的基础之上,特别是对 Landsat 数据系统性处理与应用的开拓性工作,以及利用年最大值合成法生成无云植被指数产品的成熟方法论。相较于现有同类产品,本数据集以其更长的时序覆盖、一致的处理流程和高空间分辨率,展现出巨大的潜在重用价值。研究者可借此深入探究以下科学问题:城市扩张与土地利用变化的生态效应、极端气候事件(如干旱、洪涝)对植被的冲击与恢复力、以及全球变暖背景下物候特征的长期演变趋势等。该数据集的发布预期将为生态学、地理学、气候学及农学等多个交叉学科提供一项宝贵的基础数据资源,推动数据驱动下的环境科学研究迈向更深层次。
1 数据采集和处理方法
1.1 数据采集方法
数据采集主要依靠 GEE ( Google Earth Engine )平台, 1986 - 2011 年份使用 LANDSAT/LT05/C02/T1_L2 数据集。 2012 - 2013 年使用 LANDSAT/LE07/C02/T1_L2 数据集。由于 LANDSAT7 影像的 扫描行校正器( Scan Line Corrector, SLC )的永久性故障 。因此,自 2003 年 5 月 31 日之后获取的 LANDSAT 7 影像被称为 “ SLC - off ”数据 ,在 SLC - off 影像中,每一景图像都会出现 平行的、交错的数据缺失条带 。图像中间部分几乎完整,但越往边缘,条带缺失越严重,导致边缘部分约有 22% 的数据完全丢失。 所以 2012 年和 2013 年的数据采用了核函数的方法进行了修补。 2014 - 2018 年使用 LANDSAT/LC08/C02/T1_L2 数据集。 2019 - 2025 年使用 LANDSAT/LC08/C02/T1_L2 和 LANDSAT/LC09/C02/T1_L2 数据集。
1.2 数据处理
常见问题
1986-2025年中国逐年30米分辨率最大值合成NDVI数据集是什么?
本数据集基于 Google Earth Engine (GEE)平台,通过对 Landsat 系列卫星影像进行逐年最大值合成处理,生成 1986年至 2025年中国区域 30米空间分辨率的年度 NDVI 数据集。
1986-2025年中国逐年30米分辨率最大值合成NDVI数据集的数据来源是什么?
数据来源于长时间序列的机器学习与统计模型,由地球资源数据云整理发布。
1986-2025年中国逐年30米分辨率最大值合成NDVI数据集的时间范围是什么?
数据时间跨度为 1986–2011年。
1986-2025年中国逐年30米分辨率最大值合成NDVI数据集的时间频率是什么?
该数据集时间尺度包含年尺度或逐年变化。
1986-2025年中国逐年30米分辨率最大值合成NDVI数据集的空间分辨率是多少?
该数据集空间分辨率为 30米。
1986-2025年中国逐年30米分辨率最大值合成NDVI数据集覆盖什么区域?
该数据集覆盖范围为全球。
1986-2025年中国逐年30米分辨率最大值合成NDVI数据集是如何生产或处理的?
然而,传统的低分辨率 NDVI 产品(如 NOAA AVHRR 提供的 8公里数据)难以精细刻画局地尺度的植被空间异质性,而更高分辨率的数据(如 Landsat 的 30米分辨率)虽能弥补此缺陷,却长期受限于云污染、数据缺失以及海量数据处理的计算挑战,难以便捷地形成长时间序列的分析就绪产品。
如何获取并引用1986-2025年中国逐年30米分辨率最大值合成NDVI数据集?
在本页登录后即可下载。建议引用格式:地球资源数据云. 1986-2025年中国逐年30米分辨率最大值合成NDVI数据集. https://www.gis5g.com/dataset/163